Категории водительских прав 2016 и их расшифровка
Расшифровка категорий водительских прав
Под категорией водительских прав подразумевается группа транспортных средств, которыми может управлять человек, имеющий водительское удостоверение. Управляя транспортом, на которое нет разрешения, вас могут оштрафовать и взыскать штраф, предусмотренный законом страны. Поскольку новые водительские права, которые были выпущены в 2016 году, имеют некоторые изменения, прежде чем сесть за руль автомобиля, водитель должен ознакомиться с поправками. В противном случае можно оказаться в очень неприятной ситуации.
Что можно увидеть на удостоверении?
Как любой документ, водительские права обладают лицевой и обратной стороной. Что можно увидеть на лицевой стороне?
-
Название документа и название страны, которая его выдала можно увидеть в самом верху. -
Фотография владельца размещается с левой стороны. Размер фотографии 3х4, цветная. Делается в здании ГИБДД во время выдачи удостоверения.
Размер фотографии 3х4, цветная. Делается в здании ГИБДД во время выдачи удостоверения. -
Под фотографией стоит подпись владельца. Она должна быть такой, как на всех остальных документах. -
Справой стороны можно увидеть инициалы владельца и транслитный перевод. -
Ниже – сведения о месте и дате рождения. -
В следующей строчке можно увидеть «срок годности» документа и дату выдачи. -
Еще ниже – организацию, которая выдала документ. -
5 строчка – серия и номер. -
Регион проживания. -
В самом низу – категории.
 Размер фотографии 3х4, цветная. Делается в здании ГИБДД во время выдачи удостоверения.
Размер фотографии 3х4, цветная. Делается в здании ГИБДД во время выдачи удостоверения.
На заметку: до появления новых прав, старые имели только 5 общепринятых категорий: А, В, С, D, Е.
Теперь об обратной стороне водительских прав.
-
Штрих-код, размеров 10 на 42 см, содержащий личную информацию о владельце можно увидеть с левой стороны документа. -
Под штрих-кодом, в последней строчке указаны личные сведения водителя и ограничения для общих категорий. -
Таблица, с размещением категории водительских прав размещена справа.

Категории
«А» — Позволяет ездить на двухколесных мотоциклах с прицепом и без него. Сюда относятся также трех и четырехколесные машины, вес которых не больше 400 кг.
«В» — Водители этой категории могут управлять автомобилями, масса которых, не более 3,5 тонн. Число сидений – не больше 8.
«С» — Имея данную категорию, можно управлять машинами, вес которых больше 3,5 т. и сцепленными прицепами до 750 кг.
«D» — Позволяет управлять машинами, которые имеют больше 8 мест, не считая сиденья для водителя. Под эту категорию попадают различные виды автобусов.
«М» — Можно ездить на квадроциклах и мопедах.
«Tm и Тb» — Нужна для управления троллейбусами и трамваями.
«ВЕ» — Дает право управлять транспортными средствами массой, не превышающей 3,5 т м прицепами.
«СЕ» — Почти ничем не отличается от категории «ВЕ», но позволяет управлять машинами из категории «С». Масса прицепа – не больше 750 кг.
«DЕ» — Позволяет управлять автобусами. Количество мест – больше 8. Разрешается наличие прицепа массой до 3,5 т.
Подкатегории
«А1» — Разрешается управление скутером.
«В1» — Можно водить машину, массой 550 кг. Скорость – 50 км/ч.
«С1» — Позволяет управлять автомобилем, масса которого от 3,5 до 7,5 т. Разрешен прицеп – масса до 750 кг.
«С1Е» — Практически ничем не отличается от «С1»Общая масса машины и прицепа не должна превышать 12 т.
«D1» — Позволяет управлять машинами, способными перевозить до 16 пассажиров.
«D1Е» — Можно ездить на автомобилях из категории «С», а также и прицепом.
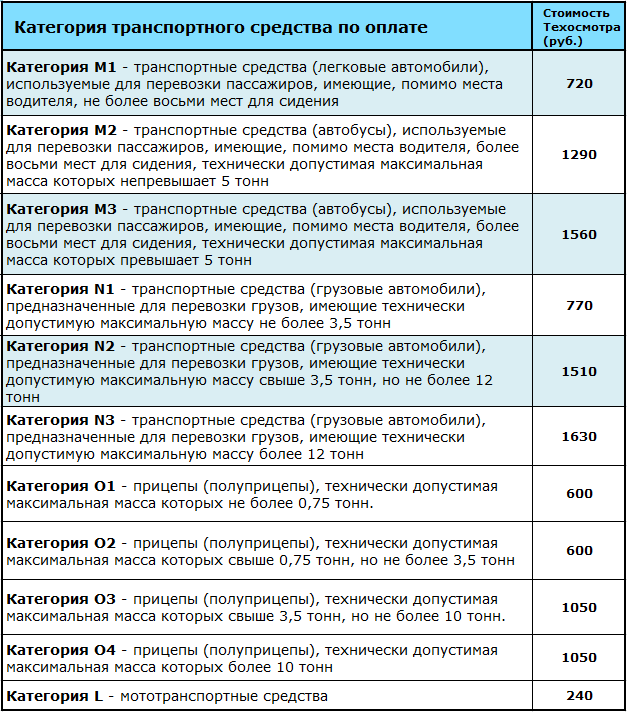
Категории водительских прав в 2020 году
Категория в правах формирует конкретную группу транспортных средств (ТС) право управлять которой имеет владелец водительского удостоверения.
С 5 ноября 2013 года вступили в силу изменения в закон «О безопасности дорожного движения», которые не только изменили перечень категорий водительского удостоверения, но и добавили совершенно новые подкатегории.
Новые категории водительских прав 2019 года — их расшифровка и классификация
Имеющиеся категории классифицируются на 7 основных:
- «A» — мотоциклы;
- «B» — легковые автомобили;
- «C» — грузовые автомобили;
- «D» — автобусы;
- «Tm, Tb» — тролебусы, трамваи;
- «M»— мопеды и скутеры;
- специальные категории «BE», «CE», «DE», «C1E», «D1E» дающие право на управление ТС с прицепом.
И 4 группы подкатегорий: «A1», «B1», «C1», «D1».
Рассмотрим подробнее каждую категорию/подкатегорию водительских прав и выясним их особенности использования для управления конкретным транспортным средством.
Категория «А» — мотоцикл
Категория «А» дает право управлять любым типом мотоциклов, в их числе — оборудованных коляской.
Кроме вышесказанного, категории «A» разрешает управлять мотоколяской (если кто-то еще помнит что это).
Напомним: в соответствии с ПДД, мотоцикл – двухколесное транспортное средство без бокового прицепа либо с ним. Категория «А» разрешает управлять трехколесным либо четырехколесным транспортным средством массой менее 400 килограмм в снаряженном состоянии.
Подкатегория «А1»
К этой подкатегории причисляют мотоцикл с объемом двигателя не более 125 см. куб., а мощностью – не более 11 кВт.
Эта подкатегория, грубо говоря, относится к мотоциклам с небольшим двигателем и невысокой мощностью.
Отметим, что человек с правами в которых категория «А» открыта может законно управлять и ТС по категории «А1».
Категория «M» — мопед / легкий квадрицикл
С 05.11.13 определена новая категория «М» для мопеда и легкого квадрицикла.
Если у человека есть права в принципе с любой открытой категорией – у него есть законное право на управление по категории «М».
Нюанс: удостоверение тракториста-машиниста права на управление обозначенными мопедами не дает.
Категория «В» — легковой автомобиль
Категория «В» в водительском удостоверении разрешает управление легковым авто и небольшими джипами/ микроавтобусами/ грузовиками, отвечающим таким требованиям:
- категория «В» — машина (за исключением ТС по категории «А») массой не более 3,5 тонны, числом мест (сидячих) не более восьми, не включая водительского;
- автомобиль категории «В» в связке с прицепом весом не более 750 кг;
- автомобиль категории «В» в связке с прицепом весом более 750 кг, но массы машины без нагрузки он не превышает, а также с условием того, что масса состава автомобиль плюс прицеп не более 3,5 тонны.
Категория «B», в том числе, разрешает управление мотоколяской, а также еще и машиной с прицепом весом не более 750 кг.
В случае если прицеп весит более 750 кг – к такому составу предъявляют дополнительные требования, а именно:
- Нагруженный прицеп не может весить больше чем машина без нагрузки;
- Разрешенный максимальный вес состава «автомобиль плюс прицеп» не может быть более 3,5 тонн.
Категория «BE» — тяжелый прицеп
Чтобы управлять машиной категории «B» в связке с тяжелым прицепом, человек должен получить категорию «BE»:
- «ВЕ» – авто категории «В» в связке с прицепом весом более 750 кг и который весит более чем сама машина без нагрузки;
- ТС категории «В» в связке с прицепом массой более 750 кг, но с условием того, что вес состава «автомобиль плюс прицеп» не должен превышать 3,5 тонн.
Подкатегория «B1» — трицикл / квадрицикл
На данный момент мы готовим подробный данные для подкатегории «B1». Ждите обновленной информации.
Сразу уточним: «квадрИцикл» и «квадрОцикл» технически разные понятия. В силу этого водительские права для квадроцикла не подходят для управления квадрициклом.
Сразу уточним: «квадрИцикл» и «квадрОцикл» технически разные понятия. В силу этого водительские права для квадроцикла не подходят для управления квадрициклом.
Категория «С» — грузовой автомобиль
Категория «C» нужна водителю для управления грузовиком весом более 3500 кг:
- категория «С» – автомобиль (кроме транспорта из категории «D») весящий более 3,5 тонн;
- машины категории «С» в связке с прицепом весом не более 750 кг.
Человек с правами категории «С» может водить только средние и тяжелые грузовики (3500-7500 кг и более 7500 кг, соответственно), а также грузовую машину с прицепом весом не более 750 кг.
Стоит обратить внимание что категория «C» абсолютно не дает водителю прав на управление небольшим грузовиком (менее 3,5 тонн) и легковой машиной.
Водительские права категории «СE» — с тяжелым прицепом
Категория «CE» пригодится водителю с открытой категорией «С» для управления автомобилем с тяжелым прицепом (больше чем 750 кг).
Подкатегория «С1»
Чтобы иметь право управлять грузовым автомобилем с весом 3,5-7,5 тонны, человек должен иметь права с действующей категорией «C1»:
- подкатегория «С1» — машины (кроме авто категории «D») с массой более 3500 килограммов, но менее 7500 килограммов;
- авто подкатегории «С1» в связке с прицепом который весит не больше чем 750 килограмм;
- к этой подкатегории относятся также и средние грузовики массой в пределах 3500-7500 кг
- подкатегория разрешает управлять связкой с легким прицепом весом до 750 кг.

Открытая категория «С» разрешает управлять машинами и по категории «С1».
Подкатегория «С1E» — тяжелый прицеп
Дополняющая подкатегория «C1E» характеризует автомобили категории «С1», однако уже весящими более 750 кг (тяжелыми прицепами). Согласно ПДД, в таком случае общий вес всего состава не должен быть более 12 тонн.
Водители со старшей подкатегорий «CE» имеют право управлять грузовиками, относящимся к категории «C1E».
Категория «D» — автобус
Чтобы иметь право управлять автобусами, человек должен обладать водительскими правами по категории «D»:
- категория «D» — транспорт перевозящий пассажиров с более чем 8 сидячими местами. Водительское место в общее число мест не входит;
- транспорт категории «D» в связке с прицепом, весящим не больше чем 750 килограмм.
Категория «D» дает право управления автобусами различных типоразмеров не зависимо от их массы, в том числе связкой «автобус плюс прицеп» с максимальный весом последнего не более 750 кг. В том случае если масса самого прицепа более 750 кг – необходима открытая категория «DE».
В том случае если масса самого прицепа более 750 кг – необходима открытая категория «DE».
Категория «DE»
«DЕ» – транспорт из категории «D» в связке с прицепом весящим более больше чем 750 килограммов. Сюда же причислен сочлененный автобус.
Подкатегория «D1»
- подкатегория «D1» — автомобиль для транспортировки пассажиров имеющий больше 8 и меньше 16 сидячих мест, не включая водительское сиденья;
- автомобиль подкатегории «D1» в связке с прицепом весом не более 750 килограмм;
Такая подкатегория разрешает управлять маленьким автобусом ( от 9 до 16 мест), а также эксплуатировать легкий прицеп (вес — менее 750 кг).
Подкатегория «D1E» — тяжелый прицеп
Если есть необходимость использовать более тяжелые прицепы – нужна будет подкатегория «D1E» для водителя автобуса:
- подкатегория «D1Е» — машины подкатегории «D1» в связке с прицепом, весящим не больше чем 750 килограмм и который не эксплуатируется для перевозки людей. Масса прицепа не должна быть больше массы самого основного транспорта без нагрузки и общая масса такой сцепки не должна быть больше 12 тонн.
 Масса прицепа не должна быть больше массы самого основного транспорта без нагрузки и общая масса такой сцепки не должна быть больше 12 тонн.
Масса прицепа не должна быть больше массы самого основного транспорта без нагрузки и общая масса такой сцепки не должна быть больше 12 тонн.Категория «D» разрешает водителю управлять ТС из категории «D1», а «DE» – из категории «D1E».
Категория «E»
На сегодня категории «E» уже не существует. Ее заменили охарактеризованные выше, категории BE, CE, C1E, DE, D1E.
В том случае если вас интересует обмен старого удостоверения с категорией «Е» — читайте наш материал «Перенос категории E в новые права«.
Категория «Tb» / «Tm» — трамвай /троллейбусы
Чтобы управлять трамваем или троллейбусом, начиная с 2016 года и уже в 2019 году, человеку потребуются права со специальной категорией «Tb» / «Tm».
Все ещё остались вопросы?
Задавайте Ваши вопросы здесь и наш автоюрист БЕСПЛАТНО ответит на все Ваши вопросы.
Последнее обновление: 04-09-2020
Какие есть категории водительских прав
Категория водительских прав — это разрешение на управление конкретным видом транспортного средства. Для получения каждой из них нужно пройти обучение и успешно сдать отдельные экзамены.
Для получения каждой из них нужно пройти обучение и успешно сдать отдельные экзамены.
Если раньше с обозначением пунктов удостоверения на право вождения авто было все понятно, то сейчас категории несколько запутаны. Помимо основных, существует целый ряд дополнительных разрешений на управление определенным видом транспорта. Для общего понимания в этой статье мы расскажем о категориях и самых популярных подкатегориях водительских прав в Украине. Плюс к этому познакомим вас с их расшифровкой. Но давайте обо всем по порядку.
Классификация водительских прав: какие бывают категории
Ранее на водительском удостоверении можно было увидеть только 5 основных категорий. Сейчас они также присутствуют, но при этом получили ряд подкатегорий. Всего современные права водителя насчитывают 16 пунктов. Их классификация базируется на общепринятой системе о дорожном движении в Украине.
В начале рассмотрим 5 основных групп транспортных средств и их значение:- Мотоциклы и мотороллеры (А) Можно водить любой двухколесный транспорт (в том числе с боковым прицепом), в котором объем двигателя не менее 50 куб. см, или электромотором мощностью более 4 кВт.
- Легковые автомобили и другой транспорт на их базе (В) Это самая распространенная среди водителей категория, которая даёт право управлять любым транспортом с массой до 3,5 тонны и общим числом сидений в салоне не более 8.
- Грузовые автомобили (С) Тут все предельно просто – можно управлять особенно крупными грузовыми авто, общая масса которых больше 7,5 тонны.
- Автобусы (D) Нужна для управления крупным пассажирским транспортным средством, в салоне которого установлено больше 16 сидений (с учетом места для водителя).
- Трамваи и троллейбусы (Т) Как видно из названия, дают право управлять трамваем и троллейбусом.
Что означают подкатегории на водительском удостоверении
Также в Украине существует ряд подкатегорий, имеющих своё индивидуальное обозначение и характеристики. Те, что с цифрой, обозначают облегченную (упрощенную) версию транспортного средства, указанного в основном разделе. Характеристика категорий с индексом Е дает разрешение на буксировку автомобилем тяжелого прицепа. Давайте рассмотрим каждый пункт более детально:
- А1 – двухколесный или трехколесный транспорт, с объемом двигателя меньше 50 куб. см. К этой подкатегории также относятся модели с электродвигателем до 4 кВт.
- В1 – малогабаритные транспортные средства, общая масса которых составляет до 400 кг. К ним относятся квадроциклы, трициклы и др.
- С1 – грузовики с разрешенной массой в диапазоне от 3,5 до 7,5 тонн.
- D1 – миниатюрные версии полноценных пассажирских автобусов. Выдается для управления транспортом с 16 местами в салоне и менее.
- В, С и D с индексом Е – управление тягачом (соответствующим основной категории), а также транспортом с прицепом (масса свыше 750 кг).
На заметку – если масса прицепа менее 750 кг, удостоверения с индексом Е не требуется. Это все описания категорий транспортных средств, которое нужно помнить водителю.
Что еще важно знать
С появлением дополнительной классификации водительских прав в Украине, существенно изменились условия для их получения. Если говорить прямо – они стали сложнее. И речь идет не только о получении первой водительской корочки. Многие водители отметили, что сдать на права даже на более низкую категорию стало значительно труднее.
Помимо усложненных экзаменов, существуют и ограничения по возрасту. Например:
- водить мотоциклы (А) можно с 16 лет,
- четырехколесный легковой и грузовой транспорт (В и С) – с 18 лет,
- прицепы и тягачи (с индексом Е) – с 19 лет,
- автобусы и троллейбусы (D и Т) только при достижении 21 года.
Расшифровка категорий водительских прав | Пдд онлайн
Здравствуйте, уважаемый автолюбитель!
Из этой статьи вы узнаете, какое отношение имеют категории водительских прав к автомобилям или на какие категории подразделяют транспортные средства. Чтобы начать управлять автомобилем, не достаточно просто получить права и начать ездить. Права нужно получить с определенной категорией.
Например, если вы хотите управлять мотоциклом, то и права должны быть с открытой категорией на право управления мотоциклами. Если хотите управлять легковым автомобилем, категория должна быть соответствующая — на право управления легковыми автомобилями. А для грузовиков и автобусов идут уже отдельные категории. Ну а теперь давайте приступим к расшифровке категорий водительских прав.
Категории водительского удостоверения обозначаются латинскими буквами. И самая первая категория начинается с первой буквы алфавита — A!
Категория A
Водительское удостоверение с отметкой «категория А» — подтверждает наличие права на управление мотоциклами, мотороллерами и другими мототранспортными средствами. Давайте обратимся к общим положениям ПДД, там написано, что «Мотоцикл» — двухколесное механическое транспортное средство с боковым прицепом или без него. К мотоциклам приравниваются трех- и четырехколесные механические транспортные средства, имеющие массу в снаряженном состоянии не более 400 кг.
Также имеется подпункт категории А, используемый для обозначения мотоциклов, количество которых не превышает 15 лошадиных сил. У таких мотоциклов, объем двигателя не превышает 125 см3. И использование таких мотоциклов разрешено с 16-ти лет.
Итак, категория «A» разрешает управлять мотоциклами.
Категория B
Водительское удостоверение с отметкой «категория В» — подтверждает наличие права на управление автомобилями, разрешенная максимальная масса которых не превышает 3500 килограммов и число сидячих мест, помимо сиденья водителя, не превышает 8. То есть вы можете управлять легковыми автомобилями, джипами и небольшими микроавтобусами. Но их разрешенная максимальная масса не должна быть более 3,5 тонн и число сидячих мест не должно быть более 8-ми, иначе это уже категория «C» или «D».
В дополнение, существует категория B1 описывающие транспортные средства с мотоциклетным мотором, массой не превышающей 550 кг и объемом двигателя до 50 см3.
С данной категорией вы можете подцепить прицеп к вашему автомобилю. Но разрешенная максимальная масса прицепа не должна превышать 750 кг, иначе это уже категория «E». Кроме этого, вам можно управлять мототранспортом масса которого превышает 400 кг.
Итак, категория «B» разрешает управлять легковыми автомобилями.
Категория C
Водительское удостоверение с отметкой категория «С» — подтверждает наличие права на управление автомобилями, за исключением относящихся к категории «D», разрешенная максимальная масса которых превышает 3500 килограммов. Эти автомобили называются грузовики. Но опять же, число сидячих мест, помимо сиденья водителя, не должно превышать 8. Так же как и в категории «B», вы можете подцепить прицеп с разрешенной максимальной массой не более 750 кг.
Подпункт категории С, который применяется к грузовым транспортным средствам общей массой от 3500 до 7500кг, обозначаемой категорией С1.
Категорией CE обозначается грузовой транспорт с прицепом, весом не более 750 кг.
И, в завершение, категорией C1E обозначается грузовой транспорт с прицепом, массой от 3500 до 7500 кг.
Итак, категория «C» разрешает управлять грузовыми автомобилями.
Категория D
Почитав предыдущие категории, вы уже поняли, что категория Д напрямую зависит от количества сидячих мест в транспортном средстве. Водительское удостоверение с отметкой категория «D» — подтверждает наличие права на управление автомобилями, предназначенными для перевозки пассажиров и имеющими более 8 сидячих мест, помимо сиденья водителя. То есть с категорией Д вы можете управлять любыми автобусами, причем не зависимо от разрешенной максимальной массы. И опять же, вы можете прицепить к автобусу прицеп, но с разрешенной максимальной массой не более 750 кг, иначе это уже следующая и последняя категория Е.
Также, имеется категория D1 описывающие автобусы малой вместимости, с количеством сидячих от 8 до 16 мест.
И, есть категория D1E применяющаяся к автобусам малой вместимости с прицепом, чей вес превышает 750 кг.
Итак, категория «D» разрешает управлять автобусами.
Категория E
Водительское удостоверение с отметкой категория «Е» — подтверждает наличие права на управление составами транспортных средств с тягачом, относящимся к категориям «В», «С» или «D», которыми водитель имеет право управлять, но которые не входят сами в одну из этих категорий или в эти категории.
Но чтобы открыть категорию «Е», у вас должны быть открыта одна из категорий (или все) B,C,D. То есть категория «Е» идет как дополнение к основным категориям. При получении категории «Е» в графу «Особые отметки» проставляются следующие отметки: E-B, E-C, E-D, E-BC, E-BD, E-CD, E-BCD. В предыдущих категориях упоминалось о прицепе. Так вот, в зависимости от того, к какому транспортному средству будет подцеплен прицеп, соответственно будет проставлена отметка.
Категория E разрешает управлять транспортными средствами:
«E-B» — с прицепом, разрешенная максимальная масса которого по крайней мере 1000 кг, а разрешенная максимальная масса состава транспортных средств превышает 3500 кг.
«E-C» — с полуприцепом или прицепом, имеющим не менее двух осей с расстоянием между ними более 1 м. «E-D» — на сочлененном автобусе.
Комбинации E-BC, E-BD, E-CD, E-BCD дают возможность управлять транспортными средствами из двух или трех подкатегорий.
Итак, категория «E» разрешает управлять транспортными средствами с прицепом.
Теперь мы знаем, на какие категории делятся транспортные средства и какие категории должны быть открыты в правах для конкретного вида транспорта. Но имейте в виду, что имя водительское удостоверение с одной категорией, например «C» (грузовики), вы не имеете право управлять легковыми автомобилями, для этого уже нужна категория «B».
В общем, чтобы управлять определенным видом транспорта, вам нужно открыть соответствующую категорию водительского удостоверения. Ну а если у вас в водительском удостоверении одна категория, а автомобиль, которым в управляете, относится к другой категории, то за это предусмотрен штраф!
На этом все, желаю вам успехов!
Содержание статьи:
- расшифровка категорий водительских прав
- водительские категории
- расшифровка водительского удостоверения
- тюфшЄхы№ёъшх ърЄхуюЁшш
Метки: Категории прав
Расшифровка всех категорий на водительских правах 2018
В последние годы правительство значительно расширило список категорий в правах водителя, которые позволяют садиться за руль разного транспорта. Кроме того, существуют ещё и подкатегории. Водителям, давно получившим права, легко запутаться в таком разнообразии, что может привести к крупному штрафу за езду на машине без открытой категории.
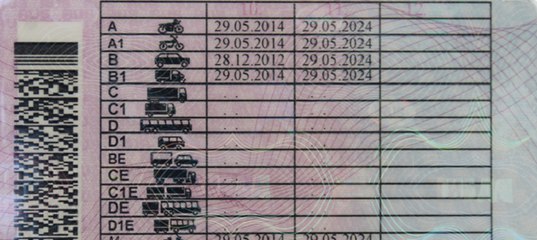
Что у вас в правах?
Не так давно появилось документ водителя нового образца, оно стало меньше по размеру и удобнее. На лицевой стороне размещен цветной снимок, автомобилисты, носящие очки, должны обязательно фотографироваться в них. Также там находятся сведения о водителе, такая как: Ф.И.О, дата и место рождения, когда и кем выданы права, а также номер. Внизу перечислены открытые водителем категории, но более подробная информация по ним расположена на обратной стороне документа.
Какие бывают категории?
На обратной стороне прав есть табличка, где отмечены все доступные автомобилисту категории транспорта. Самая первая категория – это «А». Она позволяет садиться за руль мотоцикла с коляской или без него. Мотоцикл не должен превышать вес в 400 кг и может иметь два, три или четыре колеса. Получить такое удостоверение можно совершеннолетним. Следующая подкатегория «А1» разрешает управлять только лёгкими мотоциклами, с объёмом мотора до 125 см3. Её открыть можно уже в 16 лет. Ещё существует подкатегория «М» – она разрешает ездить на маленьких мопедах и квадрициклах, чтобы её открыть нужно сдать на любую другую категорию.
Далее идёт самая популярная категория – «В», она даёт право водить легковушки весом до 3,5 тонн, в салоне которых убирается не больше 8 человек. С этой категорией можно таскать прицепы с грузоподъёмностью не больше 750 кг. Если нужно увести в прицепе больший груз, то придётся открывать дополнительную категорию – «Ве». Также есть категория «В1» – она позволяет водить квадрициклы и трициклы с движком не более 50 см3. Получить все эти категории можно, начиная с совершеннолетия.
Тяжёлая техника
Следующая категория «С» разрешает садиться за баранку машин, масса которых может превышать 7,5 тонны, чаще всего это большие грузовики. Обычная категория разрешает возить небольшой прицеп грузоподъёмностью 750 кг, для более солидных прицепов нужна категория «Се». Также существуют подкатегории «С1» и «С1е» – они отличаются тем, что позволяют управлять только более «лёгкими» грузовиками, вес которых не превышает 7,5 тонн. Получить такие права можно по достижении 18 лет.
Чтобы стать водителем автобуса, нужно открыть категорию «D» – она разрешит водить машины, в которых установлено больше 16 посадочных мест. При необходимости перевозки большого прицепа придётся открывать ещё и категорию «De». Для тех, кто собирается ездить на небольшом автобусе, создана категория «D1» и «D1е». Они позволяют управлять машинами с количеством посадочных мест от 8 до 16, а также с прицепом до 750 кг. Открыть эти категории можно всем, кто старше 21 года.
В том случае, если вы решите попробовать себя в профессии водителя трамвая или троллейбуса, то вам придётся сдавать на категории «Тв» и «Тм». Так же, как и с автобусом, сделать это могут только те, кто уже достиг возраста в 21 год.
Еще одна возможность водить?
Чтобы получить право управлять более серьёзной техникой, чем легковой автомобиль, придётся заново учиться в автошколе и опять сдавать все экзамены. Такая необходимость может возникнуть не только, когда водитель решил устроиться на работу водителем грузовика или автобуса. Есть и те, кто покупает большие машины в личное пользование, например, полноприводный грузовик «Садко» берут, чтобы ездить на охоту. Придётся переучиваться, чтобы получить права на мотоцикл, даже если у вас уже есть категория «В» в удостоверении. Также стоит учитывать, что нельзя сразу открыть подкатегорию «е», которая позволяет водить машину с большим прицепом, перед этим нужно несколько лет отъездить в основной категории.
Фото с интернет-ресурсов
Права тракториста-машиниста. Категории А1, А2, А3, А4, B,C,D,E,F.
Удостоверение тракториста-машиниста
Дает право управлять различными самоходными машинами, такими как трактора, самоходные дорожно-строительные машины, наземными безрельсовыми механическими транспортными средствами с независимым приводом, имеющими двигатель внутреннего сгорания объемом свыше 50 см3. Или электродвигатель максимальной мощностью более 4 кВт ( исключение составляют автомототранспортные средства, предназначенные для движения по автодорогам общего пользования, имеющие максимальную конструктивную скорость более 50 км/час, и боевой самоходной техники Вооруженных Сил РФ, других войск, воинских формирований и органов, выполняющих задачи в области обороны и безопасности государства).
По аналогии с автомобильными правами, в тракторных также имеются свои категории.
Рассмотрим подробнее каждую из них:
A I— внедорожные мототранспортные средства. Например, снегоходы, мотовездеходы, квадроциклы.
AII — внедорожные автотранспортные средства, разрешенная максимальная масса которых не превышает 3500 килограммов и число сидячих мест которых, помимо сиденья водителя, не превышает 8. Это аналог категории B для автомобилей с той лишь разницей, что предназначена она исключительно для внедорожных транспортных средств.
AIII — внедорожные автотранспортные средства, разрешенная максимальная масса которых превышает 3500 килограммов (за исключением относящихся к категории «А IV»), является аналогом категории C в удостоверении водителя.
AIV — внедорожные автотранспортные средства, предназначенные для перевозки пассажиров и имеющие, помимо сиденья водителя, более 8 сидячих мест (является аналогом категории D в удостоверении водителя).
Категории АII, АIII, АIV – это, фактически, всем привычные автомобильные категории «В», «С», «D», но предназначенные для движения ВНЕ автомобильных дорог. Поэтому, для их получения требуются (кроме обучения и успешной сдачи экзаменов) наличие автомобильных прав соответствующих категорий.
B — гусеничные и колесные машины с двигателем мощностью до 25,7 кВт;
C — колесные машины с двигателем мощностью от 25,7 до 110,3 кВт;
D — колесные машины с двигателем мощностью свыше 110,3 кВт;
E — гусеничные машины с двигателем мощностью свыше 25,7 кВт.
Категории В,С,D,Е – это различные трактора, отличающиеся мощностью и ходовой частью.
F — самоходные сельскохозяйственные машины: кормо- и зерноуборочные комбайны, самоходные опрыскиватели и т.д.
Для получения удостоверения тракториста-машиниста, нужно пройти обучение и сдать экзамен на право управления самоходным транспортным средством. К экзаменам допускаются следующие лица:
а) — достигшие возраста:
16 лет — для самоходных машин категории «А I»;
17 лет — для самоходных машин категорий «В», «С», «Е», «F»;
18 лет — для самоходных машин категории «D»;
19 лет — для самоходных машин категорий «А II», «А III»;
22 лет — для самоходных машин категории «А IV»;
б) — прошедшие медицинское освидетельствование и имеющие медицинскую справку установленного образца о допуске к управлению самоходными машинами соответствующих категорий, прошедшие профессиональную подготовку или получившие профессиональное образование по профессиям (специальностям), связанным с управлением самоходными машинами установленных категорий.
Допускается самостоятельная подготовка для получения права на управление самоходными машинами категорий «А I» и «В»;
в) — имеющие водительское удостоверение на право управления транспортным средством соответствующей категории и стаж управления им не менее 12 месяцев — для самоходных машин категорий «А II», «А III» и «А IV».
таблица подкатегорий водительского удостоверения, в США, В Украине, за рубежом.
Каждое водительское удостоверение имеет одну или несколько специальных категорий.
Она обозначает ту или иную группу авто — или мототранспортных средств, которой имеет право управлять гражданин на основании данного удостоверения.
Эксплуатация транспорта, входящего в другую, не обозначенную в нем категорию, запрещается и квалифицируется, как нарушение, со всеми «вытекающими» последствиями.
Содержание статьи
Содержание ВУ
Для того, чтобы лучше разобраться в вопросах водительской категории, рассмотрим сначала текст самого документа.
Итак, в нем указано:
- ФИО, год и место рождения владельца;
- номер водительского удостоверения;
- дата его выдачи и срок действия;
- наименование выдавшей организации;
- фотография и подпись владельца;
- дополнительные сведения о группе крови и др.;
- категория транспортных средств.
Важно знать, что все удостоверения, выданные на территории РФ, заполняются кириллическим (русским) алфавитом. Допускается использование символов других языков, но при обязательном дублировании слов с помощью латиницы.
Информация на удостоверении содержится с обеих сторон. С одной указаны сведения о водителе и фото, а на обратной стороне находится категория, то есть те транспортные средства, право управлять которыми получает автовладелец.
Существующие категории водительских прав
Современное отечественное законодательство предусматривает 9 водительских категорий и подкатегорий, а соответственно, 9 классификаций по массе, размерам авто и мощности двигателя.
Категория А – владелец таких прав может управлять мотоциклом общей снаряженной массой не более 400 кг. Допускается также оснащение боковым прицепом «люлькой» и наличие двух, трех или четырех колес в конструкции.
Категория В – относится к легковым автомобилям массой не выше 3,5 тонн и числом пассажирских мест не больше 8. Данная категория распространяется на ТС с прицепом, при условии, что его масса не превышает 750 кг.
Категория С – ее обладатель имеет право эксплуатировать грузовик массой до 3,5 тонн, с одним пассажирским местом и прицепом. Характеристики последнего такие же, как и в предыдущем случае.
Категория D – позволят водить пассажирские автобусы с количеством «сидячих» мест свыше 8. Допускается оснащение такого автобуса прицепом.
Категория M – распространяется на квадроциклы и мопеды с объемом «движка» до 50 см. куб. Для присвоения таких прав необходимо получить права любой другой категории.
Категории Тm и Тв – получать такие удостоверения обязаны водители троллейбусов и трамваев.
Категория ВЕ – дает возможность эксплуатировать легковые автомобили с прицепным устройством, которое тяжелее 750 кг.
Категория СЕ – во многом аналогична предыдущему варианту, с тем лишь исключением, что дополнительно позволяет управлять грузовиками с массой прицепа до 3,5 тонн.
Категория DЕ – требуется для водителей пассажирских автобусов с количеством мест более 8, оборудованных прицепным устройством до 3,5 тысяч кг.
Подкатегории водительских удостоверений
Существуют такие водительские подкатегории, которые открываются автоматически при получении основных прав.
К таковым относятся:
- подкатегория А1 – для вождения скутера;
- подкатегория В1 – для вождения трицикла и квадроцикла с максимальной скоростью до 50 км\ч и массой без груза 550 кг;
- подкатегория С1 – позволяет водить легковое авто весом от 3,5 до 7,5 тонн, оборудованное прицепным устройством до 750 кг. Такая подкатегория не дает права управлять транспортными средствами категории D;
- подкатегория С1Е – для управления «легковыми» грузовиками массой до 7,5 тонн с прицепом. Причем вес всей конструкции не должен превышать отметки в 12 тыс.кг;
- подкатегория D1 – дает право на эксплуатацию «малых» пассажирских автобусов, в которых не более 16 «сидячих» мест;
- подкатегория D1Е – подразумевает вождение «малых» автобусов с прицепным устройством, чья масса более 750 кг, а общая масса конструкции – не более 12 тонн.
Важно знать, что указанные прицепные устройства не могут использоваться для перевозки людей.
Категории прав в США
Категории водительских удостоверений в Америке сформулированы не так, как в России. Американские права классифицируются несколько непривычным для нас способом.
В первую очередь, само удостоверение бывает двух видов:
- стандартное;
- удостоверение, дающее право на управление коммерческим авто.
Стандартные права подразделяются на:
- удостоверения для вождения пассажирского авто — оно предусматривает управление большинством легкового транспорта категории В, утвержденной стандартом. В некоторых штатах приняты «собственные» названия стандартных прав. Например, во Флориде и Луизиане они называются «класс Е», в штате Миссури – «класс F», на Гавайях – «класс 10» и так далее. Данная категория не дает права на вождение мотоцикла;
- ученическое – владельцами такого удостоверения становятся лица, не достигшие 18-летнего возраста. Отличительная особенность такого документа состоит в ряде ограничений, связанных с эксплуатацией автомобиля. В частности, юным водителям запрещается управлять ТС без присутствия совершеннолетних, перевозить детей, находиться за рулем после определенного времени суток и т.д.;
- расширенное — такое удостоверение выдается только в некоторых штатах (Мичигане, Нью-Йорке, Вермонте и др.) Оно выступает в качестве документа, удостоверяющего личность гражданина. С его помощью, без паспорта, американцы могут пересекать границы смежных государств.
Удостоверения, дающие право на управление коммерческим транспортом, бывают:
- класса А – их владелец может водить комбинированный грузовой транспорт в виде тягача с прицепным устройством и составные автобусы. Причем общий вес конструкций может быть больше 26 тыс. фунтов или 11 790 кг;
- класса В – в эту категорию включены одинарные (несоставные) автобусы и грузовики массой до 26 тыс. фунтов;
- класса С – коммерческий транспорт, предназначенный для перевозки опасных веществ и грузов, а также пассажирские автомобили, способные транспортировать больше 15 человек. Данное правило не распространяется на штат Джорджия. В эту же категорию включены тягачи и трейлеры массой от 16 до 26 тыс.фунтов. В ряде штатов такие права подразделяются на коммерческие и некоммерческие. Владельцы последних не имеют права сдавать их в аренду.
Подкатегории
Американские автомобилисты, занимающиеся профессиональной водительской деятельностью, обязаны отдельно оформлять права на автомобили, вождение которых требует дополнительного обучения. Данное требование носит федеральный характер и действует на территории всех штатов.
Существует 7 подкатегорий и к ним относятся:
- L – для автомобилей с пневматическими тормозами;
- N – для транспортировки жидких грузов в цистернах;
- S – дает право на управление школьными автобусами, дополнительно требует сведений, подтверждающих отсутствие судимости;
- P – транспорт, предназначенный для перевозки пассажиров в количестве более 16 человек;
- T – тягачи и автопоезда с составными прицепами;
- H – позволяет управлять грузовиками, транспортирующими опасные вещества. Также, как и при вождении школьного автобуса, требуются сведения об отсутствии судимости;
- Х – перевозка жидких опасных веществ.
Чтобы получить права с подкатегориями Н, Х, автомобилист должен быть исключительно гражданином Соединенных Штатов. Все остальные подкатегории имеют право оформлять также и лица, имеющие вид на жительство.
Сесть за руль коммерческого автомобиля с возможностью покинуть пределы штата, американец может только по достижении 21 года.
Водить школьный автобус разрешается после 25 лет. В ряде штатов коммерческие права выдаются лицам в возрасте от 18 до 21 года с запретом выезда в соседние штаты.
Расшифровка водительских категорий на Украине
Украинское законодательство меняется довольно часто. Внезапные изменения нередко затрагивают и сферу правил дорожного движения, создавая для автовладельцев немалые сложности.
Итак, что касается категорий водительских прав на Украине, то они представлены следующими позициями:
- А1 – дает право на вождение транспортных средств с объемом «движка» не больше 50 см.куб. и мощностью до 4 кВт. Это мотороллеры, мопеды и другой транспорт, имеющий два и три колеса в конструкции;
- А – водитель с данной категорией сможет управлять мотоциклом с «люлькой» и объемом двигателя до 50 см.куб. В эту же категорию включен и любой другой двухколесный транспорт с аналогичными характеристиками;
- В1 – дает право находиться за рулем квадроцикла, трицикла и других трех- четырёхколёсных транспортных средств, весом до 400 кг;
- В – распространяется на легковые автомобили с максимальной разрешенной массой 3,5 тонны и числом пассажирских мест не более 8;
- С1 – грузовые автомобили с допустимой массой до 7,5 тонн;
- С – грузовые автомобили с допустимой массой свыше 7,5 тонн;
- Д1 – пассажирские автобусы вместимостью до 16 человек;
- Д – транспорт для перевозки пассажиров в количестве более, чем 16 человек;
Водительские удостоверения украинских автовладельцев могут иметь ряд подкатегорий:
- ВЕ – дает право на вождение легкового автомобиля, грузовика массой до 7,5 или свыше 7,5 тонн, оборудованных прицепным устройством;
- С1Е – грузовой автомобиль свыше 7,5 тонн, оборудованный прицепом;
- ДЕ – управление пассажирскими автобусами, предназначенными для перевозки более чем 16 человек, а также аналогичными ТС, перевозящими менее 16 пассажиров. По данной подкатегории автомобили должны быть оборудованы прицепом.
Несколько слов о тракторах
Для водителей специальной техники (бульдозеров, экскаваторов и др.) также существуют специальные категории. В народе такие права называют «тракторными». Их выдает не МРЭО, а Ростехнадзор. Он же присваивает категории. Всего для спецтехники их предусмотрено 6 – Aх, B, C, D, E. Классификация происходит на основе мощности двигателя и наличия гусениц.
Для получения каждой категории, водитель должен оформлять новые права и проходить дополнительное обучение.
Владельцы «обычных» автомашин не имеют права управлять ни одним из существующих видов спецтехники без нужной категории. Это же самое можно сказать и тех, кто в совершенстве владеет искусством езды на тракторах и самосвалах.
Заключение
В большинстве цивилизованных стран мира принята классификация водительских прав по категориям. Именно они дают законную возможность гражданину пользоваться транспортным средством, имеющим те или иные характеристики.
Нахождение за рулем автомобиля, не соответствующего категории водителя, считается административным правонарушением. В государствах-участниках Венской и Женевской Конвенций к таким нарушителям применяются различные санкции.
В России ответственность налагается в виде штрафа, лишения прав и помещения авто на штрафстоянку.
Чтобы избежать подобных неприятностей автомобилист, планирующий поменять свое ТС на другое, чьи технические характеристики отличаются от показателей прежней модели, обязан получить водительское удостоверение с новой категорией.
Интересное по теме:
Новая категория прав человека: нейрорайт
Неврология дает нам представление о психических процессах, лежащих в основе человеческого поведения: благодаря быстрому развитию нейротехнологий стало возможным записывать, отслеживать, декодировать и модулировать нейронные корреляты психических процессов с еще большей точностью. В этом быстро развивающемся технологическом сценарии новая статья, опубликованная в Life Sciences, Society and Policy , выступает за переосмысление и даже создание новых прав человека : — права на когнитивную свободу, психическую неприкосновенность, психическую целостность и психологическую преемственность.
Марчелло Иенка и Роберто Андорно
В пьесе « Комус », написанной Джоном Мильтоном в 1634 году, молодая дворянка похищена колдуном по имени Комус и привязана к заколдованному креслу. Несмотря на то, что ее сдерживали против ее воли, женщина постоянно отказывается от ухаживаний Комуса и заявляет: « Ты не можешь коснуться свободы моего разума», уверенная в своей способности защитить свою психическую свободу от любых внешних манипуляций.Эта идея о человеческом разуме как о высшей области абсолютной защиты от внешнего вторжения все больше устаревает благодаря достижениям нейробиологии и нейротехнологии.
Идея о человеческом разуме как о высшей области абсолютной защиты от внешнего вторжения все больше устаревает из-за достижений нейробиологии и нейротехнологий.
Передовые нейроустройства, такие как технологии нейровизуализации, нейростимуляторы и интерфейсы мозг-компьютер, позволяют записывать, отслеживать, декодировать и модулировать нейронные корреляты психических процессов с возрастающей степенью точности и разрешения.Хотя эти достижения имеют огромный потенциал для клинического и исследовательского применения, они представляют собой фундаментальную этическую, юридическую и социальную проблему : , определяющую, является ли и при каких условиях законным получение доступа к нейронной активности другого человека или вмешательство в нее.
Этот вопрос особенно актуален в контексте неклинических приложений нейротехнологии . Например, в 2008 году женщина в Индии была признана виновной в убийстве на основании обнаружения лжи с помощью мозга.Судья прямо сослался на сканирование мозга как доказательство того, что женщина обладала «эмпирическими знаниями» о преступлении, которыми мог обладать только убийца, и приговорил ее к пожизненному заключению.
Нейромаркетинг, нейроусиление и контроль мозга
Попытки получить доступ к коррелятам ментальной информации также делаются в контексте нейромаркетинга, где методы нейровизуализации обычно применяются для изучения, анализа и прогнозирования поведения потребителей и личных предпочтений. Сегодня несколько транснациональных компаний, включая Google и Disney, используют нейромаркетинговые исследовательские услуги для измерения потребительских предпочтений и впечатлений от их рекламы или продуктов.Более того, распространение недорогих, портативных и неинвазивных нейроустройств для различных целей все больше стимулирует людей делиться данными о своем мозге, аналогично тому, что наблюдалось среди пользователей других технологических устройств, таких как носимые трекеры активности. Согласно недавнему обзору, существует более 8000 действующих нейротехнических патентов, совокупная стоимость которых составляет 2 миллиарда долларов США.
Несколько транснациональных компаний используют услуги нейромаркетинговых исследований для измерения потребительских предпочтений и впечатлений от их рекламы или продуктов.Существует более 8000 активных нейротехнических патентов, совокупная стоимость которых составляет 2 миллиарда долларов США (фото с сайта Pixabay, CC0, общественное достояние)
В то время как нейротехнологии становятся все более распространенными, данные, декодируемые нейроустройствами, подвержены тем же рискам и уровням незащищенности. других секторов цифровой экосистемы, включая киберпреступлений, . Например, компьютерные ученые продемонстрировали возможность использования нейроустройств для извлечения личной информации из мозговой активности пользователей, включая информацию об их банке и домашний адрес, без их ведома.Наконец, национальные агентства обороны и безопасности из разных стран разрабатывают военные нейротехнологии, которые могут выборочно изменять умственное содержание комбатантов, улучшать их когнитивные и физические возможности, или открывать новые возможности для прямого управления мозгом военной техники или оружия.
В этом быстро развивающемся технологическом сценарии мы утверждаем, что критически важно определить, какие права люди имеют право осуществлять в зависимости от их ментального измерения.В частности, мы выступаем за переосмысление существующих прав человека и даже за создание новых прав человека , которые мы называем нейроправами: право на когнитивную свободу, право на психическую неприкосновенность, право на психическую неприкосновенность и право на психологическую преемственность.
Когнитивная свобода
Право на познавательную свободу защищает право людей принимать свободные и компетентные решения относительно использования ими нейротехнологий.В своем негативном значении он гарантирует защиту людей от принудительного и несанкционированного использования таких технологий. Мы считаем, что этот негативный компонент особенно важен для предотвращения будущих сценариев, в которых государство, крупные корпорации или злоумышленники могут насильственно манипулировать психическим состоянием отдельных граждан.
Психологическая конфиденциальность
С новыми открытиями нейронных коррелятов антисоциального поведения создание отделений полиции до преступления, как в романах Филипа Дика и в фильме Стивена Спилберга «Отчет меньшинства», не является отдаленным сценарием (фото Криса Драмма на Flickr, CC BY 2.0)
Право на неприкосновенность частной жизни направлено на защиту людей от несанкционированного вмешательства третьих лиц в данные их мозга, а также от несанкционированного сбора этих данных. Это право позволяет людям определять для себя, когда, как и в какой степени их нейронная информация может быть доступна другим.
Мы утверждаем, что нарушения конфиденциальности на нейронном уровне более опасны, чем обычные, поскольку они могут обходить уровень сознательного мышления и влиять на неотъемлемые компоненты личности человека.В ближайшем будущем, с ростом доступности общедоступных репозиториев данных мозга и параллельным прогрессом в открытии нейронных коррелятов антисоциального поведения, создание полицейских отделений Pre-Crime , как в романах Филипа Дика и фильме Стивена Спилберга. Отчет меньшинства представляет собой реальный риск, особенно в странах с установленными записями о нарушениях гражданских свобод в целях национальной безопасности.
Психическая целостность
Право на психическую неприкосновенность, , которое уже признано международным правом (статья 3 Хартии основных прав ЕС) в отношении охраны психического здоровья, должно быть расширено для защиты от незаконных и вредных манипуляций психическим здоровьем людей. активность обеспечивается нейротехнологиями.Новые формы угроз психической целостности с помощью нейротехнологий могут включать нежелательную нейростимуляцию, злонамеренный нейрохакинг и потенциально опасные манипуляции с памятью. Это право особенно актуально в контексте национальной безопасности, где потенциально вредное вмешательство в нейрокомпьютеры человека может быть оправдано в свете более высоких стратегических целей.
Право на сохранение преемственности в личности и психической жизни
Право на психологическую непрерывность направлено на сохранение личности людей и непрерывности их психической жизни от несанкционированного внешнего изменения со стороны третьих лиц, целенаправленно разработанное для обхода рациональной защиты человека и изменения его предпочтений или поведения.
Наконец, право на психологическую преемственность направлено на сохранение личности людей и непрерывности их психической жизни от несанкционированного внешнего изменения со стороны третьих лиц. В отличие от права на психическую неприкосновенность, это право применяется также к несанкционированным вмешательствам, изменяющим личность, которые не влекут за собой прямого физического или психологического вреда жертве. Помимо незаконных вмешательств, право на психологическую преемственность особенно актуально в отношении агрессивных маркетинговых стратегий, таких как те, в которых реклама целенаправленно разрабатывается так, чтобы обойти рациональную защиту человека и изменить его предпочтения или поведение.
Таким образом, мы утверждаем, что защита ментального аспекта людей от новых форм эксплуатации является серьезной социальной проблемой, которую необходимо решать на различных уровнях, в том числе на уровне основных прав. Мы полагаем, что необходимы согласованные поправки к правозащитной структуре, чтобы максимизировать преимущества нейротехнологий для общества в целом, защищая при этом основные права и свободы.
Авторы хотели бы поблагодарить Институт биомедицинской этики Базельского университета за поддержку этого исследования.
Страница не найдена
К сожалению, страница, которую вы искали на веб-сайте AAAI, не находится по URL-адресу, который вы щелкнули или ввели:
https://www.aaai.org/papers/aaai/2008/aaai08-193.pdf
Если указанный выше URL заканчивается на «.html», попробуйте заменить «.html:» на «.php» и посмотрите, решит ли это проблему.
Если вы ищете конкретную тему, попробуйте следующие ссылки или введите тему в поле поиска на этой странице:
- Выберите темы AI, чтобы узнать больше об искусственном интеллекте.
- Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».
- Выберите «Публикации», чтобы узнать больше о AAAI Press и журналах AAAI.
- Для рефератов (а иногда и полного текста) технических документов по ИИ выберите Библиотека
- Выберите AI Magazine, чтобы узнать больше о флагманском издании AAAI.
- Чтобы узнать больше о конференциях и встречах AAAI, выберите Conferences
- Для ссылок на симпозиумы AAAI выберите «Симпозиумы».
- Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «Организация».
Помогите исправить страницу, которая вызывает проблему
Интернет-страница
, который направил вас сюда, должен быть обновлен, чтобы он больше не указывал на эту страницу. Вы поможете нам избавиться от старых ссылок? Напишите веб-мастеру ссылающейся страницы или воспользуйтесь его формой, чтобы сообщить о неработающих ссылках. Это может не помочь вам найти нужную страницу, но, по крайней мере, вы избавите других людей от неприятностей. Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Если это кажется уместным, мы были бы признательны, если бы вы связались с веб-мастером AAAI, указав, как вы сюда попали (т. Е. URL-адрес страницы, которую вы искали, и URL-адрес ссылки, если таковой имеется). Спасибо!
Содержание сайта
К основным разделам этого сайта (и некоторым популярным страницам) можно перейти по ссылкам на этой странице. Если вы хотите узнать больше об искусственном интеллекте, вам следует посетить страницу AI Topics. Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».Выберите «Публикации», чтобы узнать больше о AAAI Press, AI Magazine, и журналах AAAI. Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека». Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы». Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»).Окно поиска, поддерживаемое Google, будет возвращать результаты, ограниченные сайтом AAAI.
Декодирование подкатегорий человеческого тела из областей коры головного мозга, реагирующих как на тело, так и на лицо
Основные моменты
- •
Подкатегории тела Пол и вес могут быть декодированы на основе активности мозга.
- •
Области мозга, реагирующие на тело и лицо, содержат информацию о подкатегориях тела.
- •
Кодирование подкатегории тела не зависит от размера изображения.
Абстрактное
Наша визуальная система может легко классифицировать объекты (например, лица и тела) и далее дифференцировать их на подкатегории (например, мужские и женские). Эта способность особенно важна для объектов социальной значимости, таких как человеческие лица и тела. Хотя многие исследования продемонстрировали селективность категорий лиц и тел в мозгу, остается неясным, как представлены подкатегории лиц и тел. Здесь мы исследовали, как мозг кодирует две заметные подкатегории, общие для лиц и тел, пол и вес, и зависит ли нейронная реакция на эти подкатегории от визуального сходства низкого уровня, визуального или семантического сходства высокого уровня.Мы записали активность мозга с помощью фМРТ, пока участники рассматривали лица и тела, которые различались по полу, весу и размеру изображения. Результаты показали, что пол тел можно расшифровать из областей мозга, реагирующих как на тело, так и на лицо, причем первые демонстрируют более последовательное инвариантное декодирование по размеру, чем вторые. Вес тела также можно было декодировать в областях, реагирующих на лицо, и в распределенных областях, реагирующих на тело, и это декодирование также было инвариантно к размеру изображения. Вес лиц может быть декодирован из веретенообразной области тела (FBA), а вес может быть декодирован по стимулам лица и тела в экстрастриарной области тела (EBA) и распределенной области, реагирующей на тело.Пол хорошо контролируемых лиц (например, исключая прически) нельзя было декодировать из областей, отвечающих за лицо или тело. Эти результаты демонстрируют, что участки мозга, реагирующие как на лицо, так и на тело, кодируют информацию, которая позволяет различать пол и вес тела. Более того, нейронные паттерны, соответствующие полу и весу, были инвариантны к размеру изображения и иногда могли обобщаться на стимулы лица и тела, предполагая, что такая подкатегориальная информация кодируется визуальным или семантическим кодом высокого уровня.
Ключевые слова
Восприятие тела
Восприятие лица
EBA
FBA
OFA
FFA
Рекомендуемые статьи Цитирующие статьи (0)
Просмотреть аннотацию
© 2019 Авторы. Опубликовано Elsevier Inc.
Рекомендуемые статьи
Цитирующие статьи
Общее декодирование видимых и воображаемых объектов с использованием иерархических визуальных признаков
Субъекты
Пять здоровых субъектов (одна женщина и четыре мужчины в возрасте от 23 до 38 лет) с нормальным или скорректированное до нормального зрения участвовали в экспериментах.Вместо использования статистических методов для определения размера выборки, размер выборки был выбран в соответствии с предыдущими исследованиями фМРТ с аналогичными поведенческими протоколами. Все испытуемые имели значительный опыт участия в экспериментах фМРТ и были хорошо обучены. Все субъекты предоставили письменное информированное согласие на участие в экспериментах, а протокол исследования был одобрен этическим комитетом ATR.
Визуальные изображения
Изображения были собраны из онлайн-базы данных изображений ImageNet 31 (2011, осенний выпуск), базы данных изображений, в которой изображения сгруппированы в соответствии с иерархией в WordNet 38 .Мы выбрали 200 репрезентативных категорий объектов (синсетов) в качестве стимулов в эксперименте с визуальным представлением изображений. После исключения изображений с шириной или высотой <100 пикселей или соотношением сторон> 1,5 или <2/3 все оставшиеся изображения в ImageNet были обрезаны по центру. По причинам авторского права изображения на рис. 1, 2, 3, 8 и 9 не являются фактическими изображениями из ImageNet, используемыми в наших экспериментах. Исходные изображения заменяются изображениями с аналогичным содержанием для отображения.
Схема эксперимента
Мы провели два типа экспериментов: эксперимент с изображением и эксперимент с изображениями.Все визуальные стимулы повторно проецировались на экран в отверстии сканера fMRI с использованием жидкокристаллического проектора с калибровкой яркости. Данные от каждого субъекта были собраны в течение нескольких сеансов сканирования, продолжавшихся примерно 2 месяца. В каждый день эксперимента проводился один последовательный сеанс не более 2 часов. Испытуемым давали достаточно времени для отдыха между запусками (каждые 3–10 мин) и разрешали сделать перерыв или прекратить эксперимент в любое время.
Эксперимент по представлению изображений состоял из двух различных типов сеансов: сеансов с обучающими изображениями и сеансов с тестовыми изображениями, каждый из которых состоял из 24 и 35 отдельных прогонов (9 мин 54 сек для каждого прогона), соответственно.Каждый запуск содержал 55 блоков стимулов, состоящих из 50 блоков с разными изображениями и пяти случайно перемежающихся блоков повторения, в которых было представлено то же изображение, что и в предыдущем блоке. В каждом блоке стимулов изображение (угол обзора 12 × 12 градусов) мигало с частотой 2 Гц в течение 9 с. Изображения были представлены в центре дисплея с центральной точкой фиксации. Цвет пятна фиксации менялся с белого на красный за 0,5 с до того, как каждый блок стимулов начинал указывать на начало блока.Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега, соответственно. Субъекты сохраняли устойчивую фиксацию на протяжении каждого прогона и выполняли одноразовую задачу обнаружения повторения на изображениях, отвечая нажатием кнопки для каждого повторения, чтобы удерживать свое внимание на представленных изображениях (среднее выполнение задания по пяти субъектам; чувствительность = 0,930; специфичность = 0,995). В сеансе тренировочного образа всего 1200 изображений из 150 категорий объектов (по 8 изображений из каждой категории) были представлены только один раз.В сеансе тестового изображения было представлено всего 50 изображений из 50 категорий объектов (по 1 изображению из каждой категории) по 35 раз каждое. Важно отметить, что категории в сеансе тестового изображения не использовались в сеансе тренировочного изображения. Порядок представления категорий был рандомизирован по запускам.
В эксперименте с изображениями испытуемые должны были визуально представить изображения из одной из 50 категорий, которые были представлены в сеансе тестовых изображений эксперимента по представлению изображений.Перед экспериментом 50 образцов изображений из каждой категории были выставлены для тренировки соответствия между именами объектов и визуальными образами, указанными в именах. Эксперимент с изображениями состоял из 20 отдельных прогонов, и каждый прогон содержал 25 блоков изображений (10 мин 39 с для каждого прогона). Каждый блок изображений состоял из 3-секундного периода подсказки, 15-секундного периода изображения, 3-секундного периода оценки и 3-секундного периода отдыха. Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега, соответственно.В периоды покоя в центре дисплея отображалось белое пятно фиксации. Цвет пятна фиксации изменился с белого на красный в течение 0,5 с, чтобы указать начало блоков за 0,8 с до начала каждого периода метки. Во время периода подсказки слова, описывающие названия 50 категорий, представленных в сеансе тестового изображения, были визуально представлены вокруг центра дисплея (1 цель и 49 отвлекающих факторов). Положение каждого слова было случайным образом изменено между блоками, чтобы избежать искажения специфических для сигналов эффектов на ответ фМРТ во время периодов изображения.Слово, соответствующее воображаемой категории, было выделено красным цветом (цель), а другие слова — черным цветом (отвлекающие факторы). Начало и конец периодов изображения сигнализировались звуковыми сигналами. Испытуемые должны были начать воображать как можно больше изображений объектов, относящихся к категории, описанной красным словом, и были проинструктированы держать глаза закрытыми от первого сигнала до второго сигнала. После второго звукового сигнала было представлено слово, соответствующее целевой категории, чтобы испытуемые могли оценить яркость своих мысленных образов по пятибалльной шкале (очень яркая, довольно яркая, довольно яркая, не яркая, не может распознать цель). нажатие кнопки.25 категорий в каждом прогоне были псевдослучайно выбраны из 50 категорий, так что два последовательных прогона содержали все 50 категорий.
Эксперимент с ретинотопией
Эксперимент с ретинотопией проводился по стандартному протоколу 51,52 с использованием вращающегося клина и расширяющегося кольца мерцающей шахматной доски. Данные использовались для определения границ между каждой зрительной кортикальной областью и для идентификации ретинотопической карты (V1 – V4) на сглаженных кортикальных поверхностях отдельных субъектов.
Эксперимент с локализатором
Мы провели эксперименты с функциональным локализатором для определения LOC, FFA и PPA для каждого индивидуального субъекта 53,54,55 . Эксперимент с локализатором состоял из 4–8 запусков, каждый из которых содержал 16 блоков стимулов. В этом эксперименте неповрежденные или зашифрованные изображения (угол обзора 12 × 12 градусов) из категорий лиц, объектов, домов и сцен были представлены в центре экрана. Каждый из восьми типов стимулов (четыре категории × два условия) предъявлялся дважды за цикл.Каждый блок стимула состоял из 15-секундного неповрежденного или зашифрованного предъявления стимула. Неповрежденные и зашифрованные блоки стимулов предъявлялись последовательно (порядок неповрежденных и зашифрованных блоков стимулов был случайным) с последующим 15-секундным периодом отдыха, состоящим из однородного серого фона. Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега, соответственно. В каждом блоке стимулов 20 различных изображений одного и того же типа были представлены в течение 0,3 с, после чего последовал пустой экран 0.4 с.
Получение МРТ
Данные
фМРТ были собраны с использованием 3,0-теслаового сканера Siemens MAGNETOM Trio A Tim, расположенного в центре визуализации активности мозга ATR. Для получения функциональных изображений, охватывающих весь мозг, было выполнено сканирование с чередованием T2 * -взвешенного градиента-EPI (эхо-планарное изображение) (представление изображений, эксперименты с изображениями и локализаторами: время повторения (TR), 3000 мс; время эхо (TE), 30 мс; угол поворота 80 градусов; поле зрения (FOV) 192 × 192 мм 2 ; размер вокселя 3 × 3 × 3 мм 3 ; зазор между срезами, 0 мм; количество срезов, 50) или вся затылочная доля (эксперимент с ретинотопией: TR, 2000 мс; TE, 30 мс; угол переворота, 80 градусов; FOV, 192 × 192 мм 2 ; размер вокселя, 3 × 3 × 3 мм 3 ; промежуток среза, 0 мм; количество ломтиков 30).Т2-взвешенные изображения турбо спинового эха сканировались для получения анатомических изображений с высоким разрешением тех же срезов, которые использовались для EPI (представление изображений, эксперименты с изображениями и локализатором: TR, 7020 мс; TE, 69 мс; угол поворота, 160 градусов; FOV , 192 × 192 мм 2 ; размер вокселя, 0,75 × 0,75 × 3,0 мм 3 ; эксперимент с ретинотопией: TR, 6000 мс; TE, 57 мс; угол поворота, 160 град; FOV, 192 × 192 мм 2 ; размер вокселя 0,75 × 0,75 × 3,0 мм 3 ). Также были получены тонкоструктурные изображения всей головы, подготовленные с помощью T1-взвешенной намагниченности для быстрого получения градиент-эхо (TR, 2250 мс; TE, 3.06 мс; TI, 900 мс; угол переворота, 9 град, FOV, 256 × 256 мм 2 ; размер вокселя, 1.0 × 1.0 × 1.0 мм 3 ).
Предварительная обработка данных МРТ
Первые 9-секундные сканы для экспериментов с TR = 3 с (представление изображений, эксперименты с изображениями и локализатором) и 8-секундные сканы для экспериментов с TR = 2 с (эксперимент с ретинотопией) каждого прогона были отброшены. чтобы избежать нестабильности МРТ сканера. Полученные данные фМРТ подверглись трехмерной коррекции движения с использованием SPM5 (http: //www.fil.ion.ucl.ac.uk/spm). Затем данные были зарегистрированы в анатомическое изображение высокого разрешения внутри сеанса тех же срезов, которые использовались для EPI, а затем на анатомическое изображение с высоким разрешением всей головы. Затем зарегистрированные данные были повторно интерполированы с помощью вокселей 3 × 3 × 3 мм 3 .
Для данных эксперимента по представлению изображений и экспериментов с изображениями после удаления линейного тренда внутри прогона амплитуды вокселей были нормализованы относительно средней амплитуды всего временного хода в каждом прогоне.Нормализованные амплитуды вокселей из каждого эксперимента затем усреднялись в пределах каждого 9-секундного блока стимулов (три тома; эксперимент с изображением) или в течение каждого 15-секундного периода изображения (пять объемов; эксперимент с изображениями), соответственно (если не указано иное) после сдвига данные на 3 секунды (один объем) для компенсации задержек гемодинамики.
Выбор области интереса
V1 – V4 были выделены стандартным ретинотопическим экспериментом 51,52 . Данные ретинотопического эксперимента были преобразованы в координаты Талаираха, а визуальные корковые границы были очерчены на уплощенных корковых поверхностях с помощью BrainVoyager QX (http: // www.brainvoyager.com). Координаты вокселей вокруг границы серого и белого вещества в V1 – V4 были идентифицированы и преобразованы обратно в исходные координаты изображений EPI. Воксели от V1 до V3 были объединены и определены как «LVC». LOC, FFA и PPA были идентифицированы с использованием обычных функциональных локализаторов 53,54,55 . Данные экспериментов с локализатором были проанализированы с помощью SPM5. Воксели, показывающие значительно более высокие отклики на объекты, лица или сцены, чем для зашифрованных изображений (двусторонний t -тест, нескорректированный P <0.05 или 0,01) были идентифицированы и определены как LOC, FFA и PPA соответственно. Смежная область, покрывающая LOC, FFA и PPA, была вручную очерчена на плоских кортикальных поверхностях, и область была определена как «HVC». Вокселы, перекрывающиеся с LVC, были исключены из HVC. Вокселы от V1 до V4 и HVC были объединены для определения «VC». В регрессионном анализе воксели, показывающие наивысший коэффициент корреляции с целевой переменной в сеансе обучающего изображения, были выбраны для прогнозирования каждой функции (максимум 500 вокселей для V1 – V4, LOC, FFA и PPA; 1000 вокселей для LVC, HVC и ВК).
Визуальные особенности
Мы использовали четыре типа вычислительных моделей: CNN 20 , HMAX 21,22,23 , GIST 24 и SIFT 18 в сочетании с ‘BoF’ 16 для построения визуальных особенности из изображений. Функции с фазой обучения модели (HMAX и SIFT + BoF) использовали для обучения 1000 изображений, принадлежащих к категориям, используемым в сеансе обучающих изображений (150 категорий). Каждая модель подробно описана в следующих подразделах.
Сверточная нейронная сеть
Мы использовали реализацию MatConvNet (http: // www.vlfeat.org/matconvnet/) модели CNN 20 , которая была обучена с изображениями в ImageNet 31 для классификации 1000 категорий объектов. CNN состояла из пяти сверточных слоев и трех полностью связанных слоев. Мы случайным образом выбрали по 1000 единиц в каждом из слоев с первого по седьмой и использовали все 1000 единиц в восьмом слое. Мы представили каждое изображение вектором выходных данных этих устройств и назвали их CNN1 – CNN8 соответственно.
HMAX
HMAX 21,22,23 — это иерархическая модель, которая расширяет простые и сложные ячейки, описанные Hubel и Wiesel 56,57 , и вычисляемые функции через иерархические уровни.Эти слои состоят из слоя изображения и шести последующих слоев (S1, C1, S2, C2, S3 и C3), которые построены из предыдущих слоев путем чередования операций сопоставления шаблонов и max. В расчетах на каждом слое мы использовали те же параметры, что и в предыдущем исследовании 22 , за исключением того, что количество элементов в слоях C2 и C3 было установлено на 1000. Мы представили каждое изображение вектором трех типов функций HMAX, который состоял из 1000 случайно выбранных выходных данных единиц в слоях S1, S2 и C2, и всех 1000 выходных данных в слое C3.Мы определили эти выходы как HMAX1, HMAX2 и HMAX3 соответственно.
GIST
GIST — это модель, разработанная для компьютерной задачи категоризации сцены 24 . Для вычисления GIST изображение сначала было преобразовано в шкалу серого, а его размер был изменен до максимальной ширины 256 пикселей. Далее изображение фильтровали с помощью набора фильтров Габора (16 ориентаций, 4 шкалы). После этого отфильтрованные изображения были сегментированы сеткой 4 × 4 (16 блоков), а затем отфильтрованные выходные данные в каждом блоке были усреднены для извлечения 16 ответов для каждого фильтра.Ответы от нескольких фильтров были объединены, чтобы создать 1024-мерный вектор признаков для каждого изображения (16 (ориентации) × 4 (масштаб) × 16 (блоков) = 1024).
SIFT с BoF (SIFT + BoF)
Визуальные характеристики с использованием SIFT с подходом BoF были рассчитаны на основе дескрипторов SIFT. Мы вычислили дескрипторы SIFT из изображений, используя реализацию VLFeat 58 плотного SIFT. В подходе BoF каждый компонент вектора признаков (визуальные слова) создается путем векторного квантования извлеченных дескрипторов.Используя ~ 1000000 дескрипторов SIFT, рассчитанных из независимого набора обучающих образов, мы выполнили кластеризацию k-средних, чтобы создать набор из 1000 визуальных слов. Дескрипторы SIFT, извлеченные из каждого изображения, были квантованы в визуальные слова с использованием ближайшего центра кластера, и частота каждого визуального слова была вычислена для создания гистограммы BoF для каждого изображения. Наконец, все гистограммы, полученные в результате описанной выше обработки, прошли L-1 нормализацию, чтобы стать векторами единичной нормы. Следовательно, функции из SIFT с подходом BoF инвариантны к масштабированию, перемещению и повороту изображения и частично инвариантны к изменениям освещения и аффинной или трехмерной проекции.
Декодирование визуальных признаков
Мы построили модели декодирования для прогнозирования векторов визуальных признаков видимых объектов по активности фМРТ с использованием функции линейной регрессии. Здесь мы использовали SLR (http://www.cns.atr.jp/cbi/sparse_estimation/index.html) 32 , который может автоматически выбирать важные функции для прогнозирования. Известно, что разреженная оценка хорошо работает, когда размерность объясняющей переменной высока, как в случае с данными фМРТ 59 .
Учитывая образец фМРТ, состоящий из активности d вокселей в качестве входных данных, функцию регрессии можно выразить как
, где x i — скалярное значение, определяющее амплитуду фМРТ вокселя i , w i — вес воксела i и w 0 — смещение.Для простоты смещение w 0 поглощается вектором весов, так что. Фиктивная переменная x 0 = 1 вводится в данные таким образом, что. Используя эту функцию, мы смоделировали l -й компонент каждого вектора визуальных признаков как целевую переменную t l ( l ∈ {1,…, L }), что объясняется регрессией функция y ( x ) с аддитивным гауссовым шумом, как описано в
, где ∈ — гауссова случайная величина с нулевым средним с точностью до шума β .
Учитывая набор обучающих данных, SLR вычисляет веса для функции регрессии, так что функция регрессии оптимизирует целевую функцию. Чтобы построить целевую функцию, мы сначала выражаем функцию правдоподобия как
, где N — это количество выборок, а X — это матрица данных фМРТ N × ( d +1), у которой n -я строка является d + одномерный вектор x n , и являются выборками компонента вектора визуальных признаков.
Мы выполнили оценку байесовского параметра и приняли автоматическое определение релевантности до 32 , чтобы внести разреженность в оценку веса. Мы рассмотрели оценку весового параметра w с учетом наборов обучающих данных { X , t l }. Мы приняли априорное распределение Гаусса для весов w и неинформативные априорные значения для параметров точности веса и параметра точности шума β , которые описаны как
. оцениваемые параметры и веса могут быть оценены путем оценки следующей совместной апостериорной вероятности w :
. Учитывая, что оценка совместной апостериорной вероятности аналитически трудна, мы аппроксимировали ее, используя вариационный байесовский метод 32,60 61 .Хотя результаты, показанные на основных рисунках, основаны на этой модели автоматического определения релевантности, мы получили качественно аналогичные результаты с использованием других регрессионных моделей (дополнительные рисунки 21 и 22).
Мы обучили модели линейной регрессии, которые предсказывают векторы признаков отдельных типов / слоев признаков для категорий наблюдаемых объектов по образцам фМРТ в сеансе обучающего изображения. Для наборов тестовых данных образцы фМРТ, соответствующие тем же категориям (35 образцов в сеансе тестового изображения, 10 образцов в эксперименте с изображениями), были усреднены по испытаниям для увеличения отношения сигнал / шум сигналов фМРТ.Используя изученные модели, мы предсказали векторы признаков видимых / воображаемых объектов из усредненных образцов фМРТ, чтобы построить один предсказанный вектор признаков для каждой из 50 тестовых категорий.
Синтез предпочтительных изображений с использованием максимизации активации
Мы использовали метод максимизации активации для создания предпочтительных изображений для отдельных единиц в каждом слое CNN 33,34,35,36 . Синтез предпочтительных изображений начинается со случайного изображения и оптимизирует изображение, чтобы максимально активировать целевой блок CNN, итеративно вычисляя, как изображение должно быть изменено с помощью обратного распространения.Этот анализ был реализован с использованием специального программного обеспечения, написанного в MATLAB на основе кодов Python, представленных в серии сообщений в блогах (Mordvintsev, A., Olah, C., Tyka, M., DeepDream — пример кода для визуализации нейронных сетей, https: / /github.com/google/deepdream, 2015; Ойгард, AM, Визуализация классов GoogLeNet, https://github.com/auduno/deepdraw, 2015).
Идентификационный анализ
В ходе идентификационного анализа категории видимых / воображаемых объектов были идентифицированы с использованием векторов визуальных признаков, декодированных из сигналов фМРТ.Перед анализом идентификации были вычислены векторы визуальных признаков для всех предварительно обработанных изображений во всех категориях (15 372 категории в ImageNet 31 ), за исключением тех, которые использовались в экспериментах фМРТ и их категорий гиперонимов / гипонимов, а также тех, которые использовались для визуальных обучение функциональной модели (HMAX и SIFT + BoF). Векторы визуальных признаков отдельных изображений были усреднены внутри каждой категории, чтобы создать средние по категории векторы признаков для всех категорий, чтобы сформировать набор кандидатов.Мы вычислили коэффициенты корреляции Пирсона между декодированными и средними по категории векторами признаков в наборах кандидатов. Для количественной оценки точности мы создали наборы кандидатов, состоящие из увиденных / воображаемых категорий и указанного количества случайно выбранных категорий. Ни одна из категорий в наборе кандидатов не использовалась для обучения декодера. Учитывая декодированный вектор признаков, идентификация категории проводилась путем выбора категории с наивысшим коэффициентом корреляции среди наборов кандидатов.
Статистика
В основном анализе мы использовали t -тесты, чтобы проверить, превышает ли среднее значение коэффициентов корреляции и среднее значение точности идентификации по субъектам уровень вероятности (0 для коэффициента корреляции и 50% для точность идентификации). Для коэффициентов корреляции перед статистическими тестами применялось преобразование Фишера z . Перед каждым тестом t мы выполняли тест Шапиро-Уилка для проверки нормальности и подтвердили, что нулевая гипотеза о том, что данные, полученные из нормального распределения, не была отклонена для всех случаев ( P > 0.01).
Доступность данных и кода
Экспериментальные данные и коды, подтверждающие выводы этого исследования, доступны в нашем репозитории: https://github.com/KamitaniLab/GenericObjectDecoding.
Границы | Категория Декодирование визуальных стимулов на основе активности человеческого мозга с использованием двунаправленной рекуррентной нейронной сети для имитации двунаправленных информационных потоков в зрительной коре человека
Введение
В нейробиологии визуальное декодирование было важным способом понять, как и какая сенсорная информация кодируется и представляется в зрительной коре головного мозга.Функциональная магнитно-резонансная томография (фМРТ) является эффективным инструментом для отражения активности мозга, а модели вычисления визуального декодирования, основанные на данных фМРТ, привлекают значительное внимание на протяжении многих лет (Kamitani and Tong, 2005; Haynes and Rees, 2006; Norman et al., 2006; Naselaris et al., 2011; Nishimoto et al., 2011; Horikawa et al., 2013; Li et al., 2018; Papadimitriou et al., 2018). Категоризация, идентификация и реконструкция визуальных стимулов на основе данных фМРТ — три основных средства визуального декодирования.По сравнению с идентификацией и реконструкцией категоризация или декодирование по категориям является обычным и возможным в области визуального декодирования, поскольку идентификация ограничивается набором данных фиксированного изображения, а точная реконструкция ограничивается простыми стимулами изображения.
Категориальное декодирование визуальных стимулов можно в основном разделить на три вида методов: (1) методы на основе классификаторов, (2) методы на основе сопоставления шаблонов вокселей и (3) методы на основе сопоставлений шаблонов признаков.Методы, основанные на классификаторах, выполняют декодирование категорий путем обучения статистического линейного или нелинейного классификатора, чтобы напрямую изучить отображение конкретных воксельных паттернов в зрительной коре к категориям. В предыдущей работе (Cox and Savoy, 2003) использовались классификаторы линейной машины опорных векторов (SVM) (Chang and Lin, 2011) для различения воксельных паттернов, вызываемых каждой категорией. Кроме того, также использовались различные классификаторы, включая классификатор Фишера и классификатор k-ближайших соседей (Misaki et al., 2010; Song et al., 2011). Wen et al. (2017) использовали классификатор предварительно обученной сверточной нейронной сети (CNN) (LeCun et al., 1998) для декодирования категорий. Способы, основанные на сопоставлении шаблонов вокселей, должны вычислять корреляцию между вокселями, которые должны быть декодированы, и шаблоном шаблона вокселей каждой категории, и декодирование категории может выполняться в соответствии с максимальной корреляцией. Шаблон шаблона вокселей для каждой категории (Sorger et al., 2012) должен быть построен этими методами.Haxby et al. (2001) напрямую использовали средства вокселей образцов той же категории, что и шаблон образца вокселей каждой категории. Kay et al. (2008) построили модель кодирования для прогнозирования шаблонов вокселей, используя эти образцы с соответствующей категорией, и взяли среднее значение предсказанных шаблонов вокселей в качестве шаблона шаблона вокселей для каждой категории. Методы, основанные на сопоставлении шаблонов признаков, реализуют декодирование путем сопоставления вокселей с конкретными функциями изображения, сравнения их с шаблонами шаблонов признаков каждой категории и, наконец, выбора категории с максимальной корреляцией.Третий способ зависит от промежуточного моста функций, и отображение вокселей на представления функций играет важную роль. Хорикава и Камитани (2017a) и Вен и др. (2018) построили шаблон паттерна признаков для каждой категории, усредняя предсказанные особенности CNN для всех стимулов изображения, принадлежащих к одной и той же категории. Среди этих исследований большое внимание привлекли исследования, основанные на иерархических характеристиках CNN (Agrawal et al., 2014; Güçlü and van Gerven, 2015).
В системе зрения человека зрительная кора головного мозга функционально организована в вентральный поток и спинной поток (Mishkin et al., 1983), а вентральная кора в основном отвечает за распознавание объектов. Анатомические исследования показали, что связи между брюшной корой были восходящими и нисходящими (Bar, 2003). Двунаправленные (прямые и обратные) соединения обеспечивают анатомическую структуру для двунаправленных информационных потоков в зрительной коре головного мозга. Прямые (Tanaka, 1996) и обратные потоки информации (Eger et al., 2006) играют разные роли в задачах распознавания. Визуальная информация течет от первичной зрительной коры к высокоуровневой зрительной коре, и тогда мы можем получить высокоуровневое семантическое понимание, которое известно как восходящий зрительный механизм (Logothetis and Sheinberg, 1996).Таким образом, деятельность зрительной коры в основном модулируется сенсорным входом. Помимо прямых входов, модуляция обратной связи от зрительной коры высокого уровня также может влиять на деятельность зрительной коры низкого уровня (Buschman and Miller, 2007; Zhang et al., 2008). Таким образом, визуальная информация течет от зрительной коры высокого уровня к зрительной коре низкого уровня, что известно как зрительный механизм сверху вниз (Beck and Kastner, 2009; McMains and Kastner, 2011; Shea, 2015).
Нисходящая роль в репрезентациях зрительной коры может быть облегчена и усилена с помощью задачи или цели (Beck and Kastner, 2009; Khan et al., 2009; Stokes et al., 2009; Гилберт и Ли, 2013). Например, Ли и др. (2004) продемонстрировали, что нейроны могут нести больше информации об атрибутах стимула, основываясь на нисходящем порядке, когда люди выполняют задачу. Хорикава и Камитани (2017a) показали, что категории воображаемых изображений могут быть декодированы, а Senden et al. (2019) пришли к выводу, что воображаемые буквы можно реконструировать по ранней зрительной коре головного мозга, что выявило тесное соответствие между зрительными ментальными образами и восприятием.Эти исследования предполагали, что визуальная информация может поступать из зрительной коры высокого уровня, чтобы модулировать представления коры низкого уровня на основе нисходящего способа. Более того, для тех, у кого нет задач или целей во время распознавания, визуальное внимание (Kastner and Ungerleider, 2000; Baluch and Itti, 2011; Carrasco, 2011), по-видимому, также способно облегчить нисходящую роль в репрезентациях зрительной коры. Люди могут выбрать направление внимания на интересующие области на основе механизма визуального внимания после получения семантического понимания сенсорного ввода.Таким образом, семантическая информация также может поступать от зрительной коры высокого уровня, чтобы модулировать представления зрительной коры низкого уровня.
Хотя многие работы были сосредоточены на взаимодействии (McMains and Kastner, 2011; Coco et al., 2014) между методами снизу вверх и сверху вниз, все еще неясно, что такое «верх», а что «низ» в дискуссии. о нисходящем влиянии на восприятие (Teufel and Nanay, 2017). Однако текущие анатомические и функциональные роли восходящего и нисходящего зрительного механизма действительно указывают на некоторые важные точки зрения.Высокоуровневые зрительные коры могут формировать семантические представления или знания посредством иерархической обработки информации, основанной на восходящем способе, и представления в низкоуровневых зрительных кортиках также могут модулироваться на основе нисходящего способа. Кроме того, испытуемый видел один и тот же стимул изображения в нескольких повторных испытаниях в ходе эксперимента по визуальному декодированию, и испытуемый обращал внимание на эти интересные области после понимания основного значения стимула изображения, потому что люди могут сосредоточиться только на одной части в то же время из-за конкуренции визуальных предубеждений (Desimone and Duncan, 1995).Во время обработки визуальной информации снизу вверх и сверху вниз визуальная информация часто перетекает от зрительной коры низкого уровня к зрительной коре высокого уровня и в обратном направлении. Таким образом, мы можем предположить, что двунаправленные информационные потоки несут семантические знания от зрительной коры высокого уровня. Следовательно, максимизация двунаправленных информационных потоков в зрительной коре будет иметь большое значение для декодирования категорий.
Однако три типа методов декодирования категорий игнорировали внутренние отношения между различными визуальными областями и рассматривали вокселы в выбранных зрительных корках в целом для подачи в модель декодирования.Поэтому мы ввели двунаправленные информационные потоки в нашу модель декодирования, чтобы охарактеризовать внутренние отношения. По сравнению с нейронными сетями прямого распространения, рекуррентные нейронные сети (RNN) (Mikolov et al., 2010; Graves et al., 2013; LeCun et al., 2015) могут очень хорошо работать с временными данными и широко используются при моделировании последовательностей. Общие RNN обычно имеют только одно направленное соединение от прошлых к будущим (или слева направо) узлов входной последовательности. Двунаправленные рекуррентные нейронные сети (BRNN) (Schuster, Paliwal, 1997; Schmidhuber, 2015) разделяют нейроны регулярных RNN на положительные и отрицательные направления.Два направления позволяют использовать входную информацию из прошлого и будущего текущего периода времени. Вдохновленные BRNN, мы рассматривали двунаправленные информационные потоки (одну пространственную последовательность) как одну фальшивую временную последовательность. Поэтому мы предложили подавать вокселы в каждой визуальной области как один узел последовательности в модуль двунаправленного соединения (Hochreiter and Schmidhuber, 1997; Sutskever et al., 2014). Таким образом, выходные данные модуля двунаправленной RNN можно рассматривать как представления восходящего и нисходящего способов.Категория может быть предсказана с последующим полностью подключенным слоем softmax путем комбинирования двунаправленных представлений.
В этом исследовании наши основные вклады заключаются в следующем: (1) мы проанализировали недостатки существующих методов декодирования, основанных на восходящих и нисходящих визуальных механизмах, (2) мы предложили использовать BRNN для имитации двунаправленной информации. потоки для категориального декодирования визуальных стимулов, и (3) мы проанализировали, что двунаправленные информационные потоки устанавливают внутреннюю взаимосвязь между визуальными областями, связанными с категорией, и подтвердили, что моделирование внутренней взаимосвязи имело значение для категориального декодирования.
Материалы и методы
Экспериментальные данные
Набор данных, использованный в нашей работе, был построен на основе предыдущих исследований (Kay et al., 2008; Naselaris et al., 2009). Набор данных содержал визуальные стимулы, соответствующие данные фМРТ и метки категорий, состоящий из 1750 обучающих образцов и 120 проверочных образцов. Подробную информацию о визуальных стимулах и данных фМРТ можно получить из предыдущих исследований (Kay et al., 2008; Naselaris et al., 2009), а набор данных можно загрузить с http: // crcns.org / data-sets / vc / vim-1.
Визуальные стимулы
Визуальные стимулы состояли из последовательностей естественных фотографий, которые в основном были получены из знаменитого набора данных сегментации Беркли (Martin et al., 2001). Содержание фотографий включало животных, здания, продукты питания, людей, сцены в помещении, искусственные объекты, сцены на открытом воздухе и текстуры. Фотографии были преобразованы в оттенки серого и уменьшены до 500 пикселей. Фотографии (500 × 500 пикселей), представленные испытуемым, были получены путем кадрирования по центру, маскирования с циклом, размещения на сером фоне и добавления белого квадрата размером 4 × 4 пикселей в центральном положении.Всего в качестве визуальных стимулов было выбрано 1870 изображений, которые были разделены на 1750 и 120 изображений для обучения и проверки соответственно.
Схема эксперимента
Фотографии были представлены в последовательных четырехсекундных испытаниях. Каждое испытание содержало 1 секунду представления фотографии с частотой мигания 200 мс и 3 секунды представления серого цвета. Соответствующие данные фМРТ были собраны, когда два субъекта с нормальным зрением или зрением с поправкой на нормальное просмотрели фотографии и сфокусировались на центральном белом квадрате фотографий.Эксперимент с каждым испытуемым состоял из пяти сеансов сканирования, и в каждом сеансе было пять обучающих запусков и два проверочных запуска. Семьдесят различных изображений были представлены два раза во время каждого тренировочного прогона, и 12 различных изображений были представлены 13 раз во время валидационного прогона. Изображения были выбраны случайным образом и были разными для каждого прогона. Таким образом, испытуемым были представлены все 1750 различных (5 сеансов × 5 запусков × 70) изображений и 120 различных (5 сеансов × 2 запусков × 12) изображений для обучения и проверки.
Сбор и предварительная обработка данных фМРТ
Система 4T INOVA MRI с квадратурной передающей / приемной поверхностной катушкой использовалась для получения данных fMRI. Функциональные и анатомические объемы мозга реконструировали с помощью программного пакета ReconTools https://github.com/matthew-brett/recon-tools. Время повторения (TR) составляло 1 с, а размер изотропного вокселя составлял 2 × 2 × 2,5 мм 3 в последовательности однократного градиента EPI. Полученные данные были подвергнуты серии предварительной обработки, включая фазовую коррекцию, синк-интерполяцию, коррекцию движения и совместную регистрацию с анатомическим сканированием.Что касается временных рядов предварительной обработки для каждого воксела, курсы времени отклика для конкретного вокселя были оценены на основе модели ограниченного базисного разделения (BRS) и оценки амплитуды (одно значение) откликов вокселей для каждого из них. Изображение было получено путем деконволюции курсов времени отклика из данных временных рядов для повторных испытаний. Затем ответы были стандартизированы, чтобы улучшить согласованность ответов в сеансах сканирования. Вокселы были назначены каждой визуальной области на основе эксперимента по ретинотопному картированию, проведенного в отдельных сеансах.В набор данных были собраны вокселы в пяти областях интереса (V1, V2, V3, V4 и LO) от зрительной коры низкого до высокого уровня.
Ярлыки категорий
В дополнение к изображениям-стимулам и соответствующим данным фМРТ, пять опытных людей вручную пометили 1870 изображений, соответственно, в соответствии с тремя уровнями (5, 10 и 23 категории), и окончательные метки были получены путем голосования. Как показано на Рисунке 1, набор данных с трехуровневыми категориями может всесторонне подтвердить метод декодирования от крупнозернистого до мелкозернистого.
Рисунок 1. Трехуровневые метки с 5, 10 и 23 категориями. Трехуровневые категории были разработаны для проверки предлагаемого метода по разным параметрам, что может сделать сравнение более убедительным.
Образцы (кортежи данных) в обучении и проверке
Каждый образец включал один стимул изображения, соответствующие предварительно обработанные данные фМРТ и три метки для трехуровневых категорий. Размер стимула изображения был изменен на 224 × 224, чтобы соответствовать входным данным модели кодирования (см. Раздел «Визуальное кодирование на основе характеристик CNN»).Следует подчеркнуть, что данные фМРТ образцов не имеют измерения времени. Данные фМРТ удалили измерение времени посредством предварительной обработки, и каждый воксель в визуальных областях имел одно значение отклика для одного просматриваемого изображения. Сто вокселей (один вектор) в каждой визуальной области были выбраны на основе модели кодирования. Три метки в каждой выборке использовались для разных уровней категоризации. Поскольку двум испытуемым было показано 1750 обучающих изображений и 120 проверочных изображений, набор данных содержал 1750 обучающих образцов и 120 проверочных образцов для каждого испытуемого.
Обзор предлагаемого метода
Чтобы ввести двунаправленные информационные потоки в метод декодирования, мы использовали метод на основе BRNN для имитации восходящего и нисходящего поведения в системе человеческого зрения. Таким образом, в методе декодирования можно использовать не только информацию о каждой зрительной области, но также внутренние отношения между зрительными корками. Как показано на рисунке 2, предложенная модель включает части кодирования и декодирования. Для кодирующей части мы можем получить соответствующие характеристики заданных стимулов изображения на основе преобладающего предварительно обученного ResNet-50 (He et al., 2016) модели и используют эти функции для соответствия каждому вокселю для построения модели кодирования по вокселям. В соответствии с характеристиками подгонки мы можем измерить важность каждого вокселя для всех визуальных областей. Мы выбрали фиксированное небольшое количество вокселей с более высокой предсказательной корреляцией для каждой визуальной области (V1, V2, V3, V4 и LO), чтобы предотвратить переобучение при последующем декодировании. Для части декодирования мы создали модуль RNN и использовали выбранные воксели каждой визуальной области в качестве пяти узлов входной последовательности, чтобы использовать как иерархические визуальные представления, так и двунаправленные информационные потоки в зрительной коре головного мозга.Наконец, мы объединили извлеченные функции двунаправленного модуля RNN в качестве входных данных последнего полностью подключенного слоя классификатора softmax для прогнозирования категории.
Рисунок 2. Предлагаемый способ. Иерархические особенности в глубокой сети использовались для прогнозирования воксельных паттернов в каждой визуальной области для направления кодирования. В зависимости от производительности можно выбрать ценные воксели, чтобы уменьшить размер вокселей до фиксированного числа. Чтобы предсказать категорию, последовательность вокселей, содержащая пять визуальных областей, подается в метод на основе BRNN для извлечения семантической информации из каждой визуальной области, и двунаправленная информация течет в зрительной коре головного мозга.
Раздел «Визуальное кодирование на основе функций CNN» знакомит с тем, как построить модель визуального кодирования на основе иерархических функций CNN. Раздел «Декодирование категории на основе функций BRNN» демонстрирует, как использовать BRNN для имитации двунаправленных информационных потоков для декодирования категории.
Визуальное кодирование на основе функций CNN
Мозг можно рассматривать как систему, которая нелинейно отображает сенсорную информацию в мозговой деятельности. Модель линеаризации кодирования (Naselaris et al., 2011) подтверждено и признано во многих исследованиях. Поэтому мы использовали линейную модель кодирования, которая состояла из нелинейного отображения пространства изображений в пространство признаков и линейного отображения пространства признаков в пространство активности мозга.
Нелинейное отображение из пространства изображения в пространство признаков на основе предварительно обученной модели ResNet-50
Многие работы (Agrawal et al., 2014; Yamins et al., 2014; Güçlü and van Gerven, 2015) показали, что иерархические визуальные особенности, извлеченные с помощью предварительно обученной модели CNN, продемонстрировали сильную корреляцию с нейронной активностью зрительной коры и визуальное кодирование, основанное на функциях CNN, получило лучшую производительность кодирования, чем те функции, разработанные вручную, такие как функции Габора (Kay et al., 2008). В этом исследовании мы использовали преобладающую глубокую сеть ResNet-50 для извлечения иерархических функций для визуального кодирования. Предварительно обученный ResNet-50 может распознавать 1000 типов естественных изображений (Русаковский и др., 2015) с ультрасовременной производительностью, которая демонстрирует, что сеть обладает богатыми и мощными представлениями функций.
В модели ResNet-50 50 скрытых слоев были сложены в иерархию снизу вверх. Помимо первого сверточного слоя, в сеть были включены четыре модуля (16 остаточных блоков, каждый из которых в основном состоит из 3 сверточных слоев) и последний полностью связанный слой softmax.Подробную конфигурацию сети можно увидеть в Таблице 1. По сравнению с предыдущей классической моделью AlexNet (Крижевский и др., 2012), ResNet-50 был намного глубже и содержал более мелкие иерархические функции, что полезно для кодирования. Чтобы снизить вычислительные затраты, мы выбрали только некоторые репрезентативные функции, включая результаты последней операции AvgPooling и 16 остаточных блоков для визуального кодирования. Таким образом, мы извлекли 17 видов функций для каждого стимула (1750 обучающих изображений и 120 проверочных изображений), чтобы изучить сопоставление конкретных видов функций с каждым вокселем в каждой визуальной области (V1, V2, V3, V4 и LO).В эксперименте предварительно обученную модель ResNet-50 можно загрузить с https://download.pytorch.org/models/resnet50-19c8e357.pth в рамках преобладающей инфраструктуры глубокой сети PyTorch (Ketkar, 2017).
Таблица 1. Структура модели ResNet-50.
Линейное отображение из пространства признаков в пространство действий на основе разреженной регрессии
Для каждого слоя модель линейной регрессии сопоставляет вектор признаков X с каждым вокселем y , и он определяется следующим образом:
у = Xw (1)
, где y — это матрица м на 1, а X — матрица м на n , где м — количество обучающих выборок, а n — размер признака вектор. w , матрица n на 1, является вектором взвешивания, который нужно обучить. В таблице 1 представлены размеры каждого выбранного вектора признаков. Количество обучающих выборок m (∼2 K) значительно меньше размерности признаков n (∼100 K), что является некорректной задачей. Таким образом, мы предположили, что каждый воксель может быть охарактеризован небольшим количеством признаков в векторе признаков, и регуляризованный w был разреженным, чтобы предотвратить переобучение при обучении отображению от высокой размерности вектора признаков к одному вокселю.На основании сделанного выше предположения основную проблему можно выразить следующим образом:
minww0 при условии Xw = y (2)
В этом исследовании мы использовали метод разреженной оптимизации, называемый регуляризованным поиском ортогонального соответствия (ROMP) (Needell and Vershynin, 2010), чтобы соответствовать воксельному шаблону. ROMP добавляет ортогональный элемент и групповую регуляризацию на основе алгоритма поиска совпадений (Маллат и Чжан, 1993). Подробности этих шагов алгоритма можно найти в Needell and Vershynin (2010).Мы построили модели кодирования вокселей, используя каждый из 17 различных уровней функций, и оптимизировали 17 линейных моделей для каждого вокселя. Корреляция использовалась для измерения производительности кодирования, и была вычислена средняя корреляция верхних 200 вокселей для каждой визуальной области. Признаки, которые имели наилучшую корреляцию, были выбраны в качестве окончательных признаков для кодирования этой визуальной области. На рисунке 3 представлена производительность кодирования для каждой визуальной области при использовании другого уровня функций. На рисунке особенности оптимального слоя отмечены кружком в соответствии с характеристиками кодирования.Наконец, мы выбрали 100 верхних вокселей для каждой визуальной области (V1, V2, V3, V4 и LO) в соответствии с характеристиками подгонки, и всего 500 вокселей для пяти областей были выбраны для декодирования следующей категории. На основе модели кодирования размер вокселей для каждой визуальной области был уменьшен до небольшого фиксированного числа, в то время как ценная информация была зарезервирована. Кроме того, производительность кодирования продемонстрировала, что функции низкого уровня лучше подходят для кодирования зрительной коры низкого уровня, а функции высокого уровня подходят для кодирования зрительной коры высокого уровня, что согласуется с предыдущим исследованием (Wen et al., 2018). Кроме того, мы проиллюстрировали, что выбранные воксели в визуальных областях, показанных на рисунке 4, указывают кластерное распределение для выбранных вокселей.
Рисунок 3. Производительность кодирования каждой визуальной области на основе функций ResNet-50. Для кодирования каждого вокселя в каждой визуальной области (V1, V2, V3, V4 и LO) использовалось семнадцать типов функций, и каждый узел представляет среднюю производительность кодирования 200 верхних вокселей с более высокой корреляцией. Каждый цвет представляет один тип визуальной области, а соответствующий «кружок» указывает на оптимальную производительность.Таким образом, можно выбрать оптимальные характеристики и выбрать 100 верхних вокселей для каждой визуальной области.
Рисунок 4. Распределение выбранных вокселей в визуальных областях. Белые линии разделяют пять визуальных областей (V1, V2, V3, V4 и LO). Каждая желтая точка представляет один воксель, который указывает, где находятся 100 выбранных вокселей каждой визуальной области. Эти выбранные воксели объединяются в кластеры, а не в разбросанное распределение.
Декодирование категорий на основе характеристик BRNN
Чтобы представить двунаправленные информационные потоки для моделирования взаимоотношений между зрительной корой, мы использовали преобладающий модуль долговременной краткосрочной памяти (LSTM) в методе декодирования для извлечения характеристик категории из пространственной последовательности, состоящей из пяти визуальных областей.Тогда категория может быть предсказана через полностью подключенный слой softmax.
Модуль РНН
Долговременная кратковременная память (Hochreiter, Schmidhuber, 1997; Sutskever et al., 2014) является известным модулем RNN во многих вариантах RNN (Cho et al., 2014; Greff et al., 2016) и широко используется в приложения последовательного моделирования. В этом исследовании мы использовали двунаправленный LSTM для характеристики двунаправленных информационных потоков в зрительной коре, а двунаправленный LSTM можно легко построить, добавив двунаправленные (прямые и обратные) соединения на основе LSTM.Следовательно, мы сначала рассмотрели LSTM, и за подробным описанием читатель может обратиться к следующему блогу: http://colah.github.io/posts/2015-08-Understanding-LSTMs/.
Долговременная кратковременная память обычно дополняется повторяющимися воротами, называемыми воротами «забыть», и может предотвратить исчезновение или взрыв ошибок обратного распространения. LSTM может изучать задачи, требующие воспоминаний о событиях, которые произошли ранее. LSTM включает три логических элемента («забыть», «вход» и «выход»), которые зависят от предыдущего состояния h t – 1 и текущего входа x t .Элемент «забыть» может управлять степенью забывания предыдущей информации в соответствии с f t , вычисленным с помощью уравнения (3), где σ представляет сигмовидную функцию для ограничения f t от 0 до 1. Таким образом , LSTM может включать долговременную или кратковременную память по мере необходимости, настраивая f t . «Входной» вентиль может контролировать, насколько подавать текущий вход x t в вычисление в соответствии с i t , вычисленным с помощью уравнения (4).«Выходной» вентиль может управлять, сколько информации нужно выводить в соответствии с o t , вычисленным с помощью уравнения (5).
ft = σ (Wf⋅ [ht-1, xt] + bf) (3)
it = σ (Wi⋅ [ht-1, xt] + bi) (4)
ot = σ (Wo⋅ [ht-1, xt] + bo) (5)
На основе трех вентилей LSTM может вычислить состояние c t и h t через уравнения (6) и (7), которое также является выходом текущего вычисление.
ct = ft⋅ct-1 + it⋅ {𝑡𝑎𝑛ℎ (Wc⋅ [ht-1, xt] + bc)} (6)
ht = ot⋅𝑡𝑎𝑛ℎ (ct) (7)
Предлагаемая архитектура
Соединения в модуле RNN обычно имеют только одно направление (слева направо), но BRNN добавляет другое направление (справа налево), чтобы сделать модуль двунаправленным. На основе двунаправленного модуля LSTM мы представили архитектуру декодирования категорий.
Как показано на рисунке 5, входными данными для архитектуры являются вокселы, выбранные из пяти визуальных областей (V1, V2, V3, V4 и LO), которые составляют одну последовательность пробелов, следовательно, длина последовательности равна пяти.Согласно разделу «Визуальное кодирование на основе характеристик CNN» мы выбрали 100 вокселей для каждой визуальной области. Поскольку воксели не имеют измерения времени, 100 выбранных вокселей из каждой области рассматривались как один узел (вектор 100-D) входной последовательности, которая была передана в двунаправленный модуль LSTM. Таким образом, каждый узел также можно рассматривать как один момент (t 1 , t 2 , t 3 , t 4 и t 5 ) поддельного временного ввода. По сути, мы использовали моделирование пространственной последовательности вместо временной последовательности для категории, и мы использовали двунаправленную LSTM для характеристики пространственных (несколько визуальных областей) серий отношений вместо временных рядов отношений для каждого воксела, что является важной характеристикой. нашего метода.
Рисунок 5. Модель декодирования категорий на основе модуля BRNN. Все визуальные области рассматриваются как одна последовательность, и модуль BRNN особенно хорош при моделировании последовательности. Красная линия указывает восходящие информационные потоки, а зеленая линия указывает нисходящие информационные потоки в зрительной коре головного мозга. Комбинация характеристик с двух направлений используется для прогнозирования категории. Таким образом, информация из каждой зрительной области и двунаправленные информационные потоки в зрительной коре могут использоваться для декодирования.
Один уровень двунаправленного LSTM был добавлен в качестве входного уровня в архитектуре декодирования, чтобы охарактеризовать взаимосвязь во входной последовательности. Направления слева направо и справа налево характеризуют поведение человека снизу вверх и сверху вниз в системе человеческого зрения соответственно. Таким образом, на выходные характеристики одного узла влияют левые зрительные коры нижнего уровня и зрительные коры правого верхнего уровня. Следовательно, характеристики категории в каждой визуальной области и отношения между областями могут быть извлечены.Затем предложенный метод объединил выходные характеристики с двух направлений и подал их в последовательный полностью связанный слой softmax для прогнозирования категории. Кроме того, потеря фокуса (Lin et al., 2017) с гаммой 5.0 использовалась во время обучения для работы с трудными выборками. Что касается деталей архитектуры, входной узел был 100-D, а выход узла в каждом направлении LSTM был 16-D особенностью. Таким образом, для следующей классификации был получен 32-мерный признак, сочетающий два направления.Количество узлов в последнем полностью подключенном слое softmax составляло 5, 10 и 23 для трехуровневых меток соответственно. Мы добавили операцию выпадения со скоростью 0,5 за выводом двунаправленного LSTM, чтобы избежать переобучения. Наконец, в модели декодирования использовалась не только визуальная информация в каждой визуальной области, но и взаимосвязь между областями.
Предлагаемый метод может быть обучен сквозным образом с использованием алгоритмов, аналогичных стандартным RNN. Благодаря обучению в глубокой сетевой структуре PyTorch (Ketkar, 2017) двунаправленные информационные потоки, включая информацию о категориях, могут быть добыты на основе обучающих выборок.Во время обучения мы установили размер пакета равным 64 и использовали оптимизацию Адама, в которой скорость обучения составляла 0,001, а регуляризация веса была 0,001, для обновления параметров. На обучение в системе Ubuntu 16.04 с одной видеокартой NVIDIA Titan Xp потребовалось около 200 эпох.
Результаты
Традиционные линейные и нелинейные классификаторы
Мы выбрали несколько классических классификаторов, включая дерево решений (DR), случайный лес (RF), AdaBoost (AB), линейный и нелинейный SVM.Декодирование трехуровневой категории (5, 10 и 23) было выполнено на основе этих традиционных классификаторов. Для декодирования с 5 категориями на рисунке 6 эти традиционные методы с использованием одной визуальной области были более точными, чем случайные, и даже первичные визуальные области полезны для декодирования семантической категории. Линейный тренд производительности декодирования от зрительной коры низкого уровня к высокому также изображен на рисунке, который показывает, что производительность декодирования была улучшена. Это явление указывало на то, что больше семантической информации было получено из визуальных областей более высокого уровня.Кроме того, эти классические классификаторы обеспечивают лучшую производительность декодирования, когда все визуальные области используются вместо одной визуальной области, что указывает на то, что представления категории в разных визуальных областях дополняют друг друга. Результаты двух других уровней (10 и 23 категории) декодирования продемонстрировали аналогичное явление, которое показано на рисунках 7, 8. Кроме того, были рассчитаны среднее значение и дисперсия точности декодирования по результатам пяти повторных экспериментальных тестов с теми же гиперпараметрами. и нанесены на рисунки 6–8.Следует отметить, что дисперсия устойчивого линейного и нелинейного SVM и классификатора AB была равна нулю. Из рисунков видно, что точность декодирования SVM была выше, чем у других методов (DR, RF и AB), а производительность линейной и нелинейной SVM была аналогичной. Кроме того, эффективность S1 была выше, чем у S2, что согласуется с предыдущими исследованиями (Kay et al., 2008).
Рисунок 6. Расшифровка пяти категорий с помощью обычных классификаторов.Представлены точности различных обычных классификаторов при использовании только одной визуальной области и всех визуальных областей («V»). Можно наблюдать распределенные, иерархические и дополнительные представления семантической категории в системе человеческого зрения (подробный анализ в разделе «Обсуждение»).
Рисунок 7. Расшифровка 10 категорий с помощью обычных классификаторов.
Рисунок 8. Расшифровка 23 категорий с помощью обычных классификаторов.
Полностью подключенная нейронная сеть
В дополнение к традиционным классификаторам в разделе «Обычные линейные и нелинейные классификаторы» также был протестирован метод полносвязной нейронной сети (NN). Чтобы сравнить и проверить эффект моделирования двунаправленных информационных потоков, в методе NN использовалась архитектура, аналогичная предложенному методу, за исключением модуля RNN. В частности, метод NN имел три полностью связанных слоя. Количество нейронных узлов каждого слоя составляло 500, 64 и 32 соответственно.«500» было получено из комбинации выбранных вокселей в пяти визуальных областях. Выходы последнего полностью подключенного слоя softmax были 5-D, 10-D и 23-D для трехуровневых меток соответственно. Подобные гиперпараметры использовались во время тренировки. Таким образом, разница между методами на основе NN и BRNN заключалась в том, моделировались ли двунаправленные информационные потоки. Из рисунка 9 видно, что метод NN имеет лучшие или сравнительные характеристики относительно линейных и нелинейных методов SVM.Мы проанализировали преимущества мощной нелинейной способности нейронных сетей.
Рисунок 9. Количественное сравнение производительности декодирования для разных методов. Обычные методы и метод NN могут задействовать все визуальные области. Однако метод NN с мощной нелинейной способностью обеспечивает более высокую точность. Методы на основе BRNN с мощными нелинейными возможностями также могут использовать дополнительную информацию (двунаправленные информационные потоки), что обеспечивает лучшую производительность.
Предлагаемый метод
Как показано на рисунке 9, предложенный нами метод имел лучшую производительность для всех трех уровней декодирования категорий, поскольку он может дополнительно использовать двунаправленные информационные потоки в зрительной коре головного мозга. В таблице 2 представлена точность нашего метода, и точность декодирования по 5, 10 и 23 категориям достигла 60,83 ± 1,17%, 46,17 ± 0,42% и 39,50 ± 0,85% соответственно. Предложенный метод улучшился более чем на 5% по сравнению с другими лучшими методами.Аналогичные результаты для испытуемого S2 можно найти в таблице 3. Чтобы проверить статистическую значимость, мы вычислили соответствующие значения p , чтобы измерить разницу между предложенным методом и другими классификаторами в таблице 4. Он показал, что большинство значений значимости достигнуто. более высокий уровень ( P <0,001), что подтвердило значимость предложенного метода. Более того, минимальные значения значимости для каждого уровня категории были подчеркнуты в таблице 4, а значения значимости находились между ( P <0.01) и ( P <0,05), которые продемонстрировали приемлемую статистическую значимость. Подчеркнутые значения указывают на то, что предлагаемый нами метод показал значимость, даже несмотря на то, что использовались более строгие сравнения, в которых мы сравнивали предлагаемый метод с лучшими из всех других методов. Кроме того, на Рисунке 10 представлена матрица неточностей, отражающая подробные результаты классификации, и показано, что большинство образцов классифицированы правильно. Однако класс «текстура» показал худший результат, и мы представили два изображения, соответствующие данные фМРТ которых были классифицированы неправильно.Один был ошибочно отнесен к классу «естественный», а другой - к классу «созданный руками человека». Визуальные атрибуты двух изображений действительно были похожи на атрибуты изображений, принадлежащих к «естественным» и «искусственным» классам. Более того, классы «человек» и «животное» легко перепутать, что может быть результатом схожести визуальных атрибутов между классами «человек» и «животное».
Таблица 2. Количественное сравнение характеристик декодирования для разных методов для субъекта S1.
Таблица 3. Количественное сравнение характеристик декодирования различными методами для субъекта S2.
Таблица 4. Статистическая значимость предлагаемого нами метода по сравнению с другими методами для испытуемых S1 и S2.
Рисунок 10. Нормализованная матрица неточностей результатов и два примера ошибочной классификации для предложенного метода. Нормализованная матрица путаницы представляет подробную ошибочную классификацию, и два образца изображений используются для анализа класса («текстуры»), который имеет худшие характеристики классификации.
Эффект прямой, обратной и двунаправленной связи
Кроме того, мы сравнили точность модуля RNN при использовании прямого, обратного и двунаправленного соединений. Двунаправленные соединения включали прямые и обратные соединения. Прямые связи характеризовали восходящие информационные потоки, а обратные связи характеризовали нисходящие информационные потоки в визуальных областях. Мы сравнили двунаправленные соединения (двунаправленный LSTM) с прямыми соединениями (LSTM с входом V1 → V 2 → V 3 → V 4 → последовательность LO), обратными соединениями (LSTM с входом LO → V 4 → V 3 → V2 → V1 последовательность) и без повторяющихся соединений (полностью связанный слой с вводом всех визуальных областей в целом).Соответствующие результаты были представлены в Таблице 5. Мы видим, что метод на основе LSTM («→ •»), который характеризует восходящие информационные потоки, ведет себя лучше, чем метод NN без повторяющихся соединений и LSTM («←≤») — на основе метода, характеризующего нисходящие информационные потоки. Тем не менее, использование двунаправленных соединений по-прежнему давало преимущества, поскольку было охарактеризовано больше взаимосвязей и использовалось больше визуальной информации. Двунаправленные методы на основе LSTM в целом показали наилучшие результаты согласно среднему значению в Таблице 5 за счет комбинирования соединений LSTM («→ •») и LSTM («←»).Мы также вычислили значения значимости для измерения разницы между LSTM («→ •») и двунаправленным LSTM («→ • и ←»). Для субъекта 1 значения значимости для декодирования по 5, 10 и 23 категориям составили 7,83 × 10 –4 , 7,72 × 10 –3 и 4,34 × 10 –5 , соответственно. Для субъекта 2 значения значимости для декодирования по 5, 10 и 23 категориям составили 3,07 × 10 –1 , 2,41 × 10 –2 и 5,31 × 10 –3 , соответственно. Эти результаты показали определенное различие между LSTM («→ •») и двунаправленным LSTM («→ • и ←»), а точность задачи декодирования для субъекта 1 имеет более высокие значения значимости, чем для субъекта 2.В заключение, одиночные соединения LSTM («←») вели себя немного хуже, чем метод на основе NN, но улучшение подтвердило роль LSTM («←»). Следовательно, для декодирования необходимы двунаправленные соединения, характеризующие восходящие и нисходящие информационные потоки.
Таблица 5. Сравнение того, используются ли прямые, обратные и двунаправленные соединения для модуля RNN.
Обсуждение
Известно, что визуальное декодирование предназначено для изучения того, что существует в зрительной коре головного мозга, но легче исследовать паттерн визуальных представлений в системе человеческого зрения.Таким образом, мы пришли к выводу о некоторых существующих моментах и суммировали сходства и различия между нашим методом и другими. Кроме того, были обсуждены методы визуального декодирования на основе CNN и RNN, чтобы продемонстрировать преимущества и ограничения предлагаемого нами метода, и был представлен наш вклад в эту область.
Некоторое соответствие с предыдущими исследованиями
Известно, что низкоуровневые и высокоуровневые функции глубоких сетей сосредоточены на подробной и абстрактной информации соответственно (Mahendran and Vedaldi, 2014).С точки зрения визуального кодирования, рисунок 3 показывает, что низкоуровневые и высокоуровневые функции подходят для кодирования зрительной коры низкого и высокого уровня соответственно, что было показано в серии предыдущих исследований (Güçlü and van Gerven, 2015; Eickenberg et al., 2016; Horikawa, Kamitani, 2017b). С точки зрения визуального декодирования рисунки 6–8 нашего исследования показывают линейное улучшение от зрительной коры низкого уровня к зрительной коре высокого уровня, что может быть дополнением к методам визуального кодирования на основе CNN для поддержки иерархических представлений в визуальном коры.
Когда только одна конкретная визуальная область используется в разных классификаторах, производительность декодирования категории лучше, чем случайная, и даже визуальные области низкого уровня могут способствовать декодированию категории, что указывает на то, что визуальные области низкого уровня могут содержать визуальную информацию о категориях . Таким образом, как и в предыдущей работе (Haxby et al., 2001; Cox and Savoy, 2003), можно сделать вывод о распределенных представлениях категорий в зрительной коре головного мозга. Например, Haxby et al. (2001) продемонстрировали, что в вентральной коре головного мозга были распределены изображения лиц и предметов.Основываясь на двунаправленных информационных потоках, мы предположили, что распределенные представления могут быть вызваны динамическими информационными потоками. Визуальная информация из зрительных областей нижнего уровня может перетекать в зрительные области верхнего уровня, а визуальная информация из зрительных областей коры верхнего уровня также может перетекать в зрительные корковые области нижнего уровня. Следовательно, зрительные области в вентральной коре являются интерактивными, что может способствовать распределению репрезентаций в зрительной коре.
Результаты показывают, что производительность декодирования с использованием пяти визуальных областей превосходит использование только одной отдельной области.Улучшение подтверждает, что эти представления в различных визуальных областях не являются избыточными, а содержат различную информацию. Результаты кодирования, основанные на иерархической CNN (см. Рисунок 3), показали, что низкоуровневые функции подходят для кодирования первичной зрительной коры, а высокоуровневые функции более полезны для кодирования высокоуровневой зрительной коры. Учитывая, что низкоуровневые и высокоуровневые функции глубокой сети сосредоточены на подробной и абстрактной информации (Mahendran and Vedaldi, 2014), улучшение дополняет точку зрения о том, что низкоуровневые зрительные коры в основном обрабатывают низкоуровневые представления (граница, текстура , и цвет) и что высокоуровневые зрительные коры в основном отвечают за высокоуровневые репрезентации (форма и объект).Более того, дополнительные изображения указывают на то, что следует рассмотреть больше визуальных областей. Однако это исследование охватывает только пять зрительных областей, что является ограничением, а в некоторых предыдущих исследованиях даже упоминается меньшее количество зрительных корковых областей (Senden et al., 2019). Следовательно, следующим направлением может стать использование большего количества визуальных областей в методе декодирования и моделирование более сложных отношений в визуальных областях.
Корреляционные представления о категории в зрительной коре
За исключением иерархических, распределенных и дополнительных представлений о категориях в зрительной коре, результаты на рисунке 9 продемонстрировали, что мы можем получить улучшение примерно на 5% после введения двунаправленных информационных потоков и моделирования внутренних отношений в методе декодирования, что указывает на то, что взаимосвязь между визуальные области могут содержать семантическую информацию категорий и могут способствовать декодированию.Это показывает, что эти зрительные области связаны, а представления категорий в зрительной коре коррелятивны. Соответствующие представления категорий означают, что отношения между визуальными областями содержат атрибуты категорий. Поскольку мы не нашли литературы, в которой моделировались бы корреляционные представления для декодирования категорий из данных фМРТ, мы попытались проанализировать происхождение явления в соответствии с двунаправленными информационными потоками. А именно, семантическое знание сначала формируется посредством восходящей иерархической обработки сенсорной информации.Затем семантическая информация может поступать от зрительной коры высокого уровня для модуляции нейронной активности зрительной коры низкого уровня из-за задачи или внимания. Таким образом, мы можем сделать вывод, что семантическая информация, содержащаяся в отношении, происходит от восходящей визуальной обработки и нисходящей визуальной модуляции, а отношение связано с категориями из-за эффекта нисходящего способа. Текущие методы, такие как преобладающие методы на основе CNN, не могут моделировать визуальный механизм сверху вниз и обычно учитывают только иерархические представления.
Отличие от преобладающих CNN и RNN на основе методов визуального декодирования
Целью нашего исследования является прямое декодирование категорий из вокселей (деятельности фМРТ) с использованием классификатора на основе модуля RNN. Известно, что CNN очень эффективны для задач визуального распознавания за счет извлечения иерархических и мощных функций из 2D-изображений. Таким образом, CNN особенно подходят для визуального кодирования, но не для классификации вокселей (1D). Как показано в разделе «Визуальное кодирование на основе функций CNN», функции, извлеченные CNN, используются для кодирования вокселей для выбора ценных вокселей.Кроме того, CNN могут выполнять декодирование косвенным способом, называемым «методами на основе сопоставления шаблонов признаков» (Han et al., 2017; Horikawa and Kamitani, 2017a), который существенно отличается от нашего метода под названием «Методы на основе классификаторов, », Который является наиболее прямым способом декодирования. Кроме того, своего рода «методы, основанные на сопоставлении шаблонов признаков», берут целые визуальные области в целом и сопоставляют их с функциями CNN, что затрудняет использование внутренних отношений между вокселями.Однако RNN обычно используются для моделирования данных последовательности, а методы на основе RNN (Spampinato et al., 2017; Shi et al., 2018) могут характеризовать данные с измерением времени в области визуального декодирования. Например, Spampinato et al. (2017) предложили использовать RNN для извлечения признаков из данных ЭЭГ для декодирования, и они использовали модуль LSTM для характеристики временных рядов взаимосвязи. В качестве улучшения мы использовали модуль LSTM, чтобы охарактеризовать пространственную (несколько визуальных областей) серию отношений, поскольку измерение времени для данных фМРТ обычно не слишком сильно учитывается в области визуального кодирования и декодирования.Более конкретно, их последовательность состоит из разных временных точек для каждого воксела, но последовательность для наших RNN состоит из вокселей в разных визуальных областях, что является существенным различием между нашим методом и другими основанными на RNN методами. В заключение, наш метод является прямым и новым, потому что мы используем моделирование пространственной последовательности вместо временной последовательности для категории. Таким образом, следующим направлением визуального декодирования может быть характеристика пространственно-временной последовательности вокселей в визуальных областях.
Заключение
В этом исследовании мы проанализировали недостатки существующих методов декодирования с точки зрения двунаправленных информационных потоков (визуальные механизмы снизу вверх и сверху вниз). Чтобы охарактеризовать двунаправленные информационные потоки в зрительной коре, мы использовали модуль BRNN для моделирования пространственного ряда отношений вместо общего временного ряда отношений. Мы рассматривали выбранные воксели каждой визуальной области (V1, V2, V3, V4 и LO) как один узел в пространственной последовательности, которая подавалась в BRNN для дополнительного извлечения функций взаимосвязи, связанных с категорией, для повышения производительности декодирования.Мы проверили наш предложенный метод на наборе данных с тремя уровнями меток категорий (5, 10 и 23). Экспериментальные результаты показали, что предлагаемый нами метод позволяет получать более точные результаты декодирования, чем другие линейные и нелинейные классификаторы, при этом подтверждая статистическую значимость двунаправленных информационных потоков для декодирования категорий. Кроме того, основываясь на экспериментальных результатах, мы пришли к выводу, что представления в зрительной коре были иерархическими, распределенными и дополнительными, что соответствовало предыдущим исследованиям.Что еще более важно, мы проанализировали, что двунаправленные информационные потоки в зрительной коре коры заставляют отношения между областями содержать представления категорий и могут быть успешно использованы на основе BRNN, которую мы назвали коррелятивными представлениями категорий в зрительной коре.
Взносы авторов
KQ участвовал во всех этапах исследовательского проекта и написании статей. JC разработал процедуры общих экспериментов. LW способствовал идее декодирования на основе BRN.CZ внесла свой вклад в реализацию идеи. Л.З. участвовал в подготовке статьи, рисунков и диаграмм. LT ввел восприятие иерархических, распределенных, дополнительных и коррелятивных представлений в зрительной коре. BY предложил идею и написание.
Финансирование
Эта работа была поддержана Национальным планом ключевых исследований и разработок Китая (№ 2017YFB1002502) и Национальным фондом естественных наук Китая (№№ 61701089 и 162300410333).
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Список литературы
Агравал П., Стэнсбери Д., Малик Дж. И Галлант Дж. Л. (2014). Пиксели в воксели: моделирование визуального представления в человеческом мозге. препринт arXiv arXiv: 1407.5104.
Google Scholar
Бушман, Т.Дж., И Миллер, Э. К. (2007). Контроль внимания сверху вниз по сравнению с контролем снизу вверх в префронтальной и задней теменной коре. Наука 315, 1860–1862. DOI: 10.1126 / science.1138071
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Chang, C.-C., and Lin, C.-J. (2011). «Транзакции ACM в интеллектуальных системах и технологиях (TIST)», в LIBSVM: Библиотека для опорных векторных машин , Vol. 2, (Нью-Йорк, Нью-Йорк: ACM Press). DOI: 10,1145 / 1961189.1961199
CrossRef Полный текст | Google Scholar
Чо, К., Ван Мерриенбор, Б., Гульчере, К., Богданау, Д., Бугарес, Ф., Швенк, Х., и др. (2014). Изучение представлений фраз с использованием кодировщика-декодера RNN для статистического машинного перевода. препринт arXiv arXiv: 1406.1078.
Google Scholar
Коко, М. И., Малькольм, Г. Л., и Келлер, Ф. (2014). Взаимодействие механизмов снизу вверх и сверху вниз в визуальном руководстве во время именования объектов. Q. J. Exp. Psychol. 67, 1096–1120. DOI: 10.1080 / 17470218.2013.844843
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кокс, Д. Д., и Савой, Р. Л. (2003). Функциональная магнитно-резонансная томография (фМРТ) «чтение мозга»: обнаружение и классификация распределенных паттернов активности фМРТ в зрительной коре головного мозга человека. Neuroimage 19, 261–270. DOI: 10.1016 / s1053-8119 (03) 00049-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Дезимоне, Р.и Дункан Дж. (1995). Нейронные механизмы избирательного зрительного внимания. Annu. Rev. Neurosci. 18, 193–222. DOI: 10.1146 / annurev.neuro.18.1.193
CrossRef Полный текст | Google Scholar
Эгер, Э., Хенсон, Р., Драйвер, Дж., И Долан, Р. Дж. (2006). Механизмы облегчения нисходящего восприятия визуальных объектов, изучаемых с помощью фМРТ. Cereb. Cortex 17, 2123–2133. DOI: 10.1093 / cercor / bhl119
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Айкенберг, М., Грамфорт, А., Вароко, Г., Тирион, Б. (2016). Видеть все: слои сверточной сети отображают функции зрительной системы человека. Neuroimage 152, 184–194. DOI: 10.1016 / j.neuroimage.2016.10.001
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Грейвс, А., Мохамед, А.-Р., и Хинтон, Г. (2013). «Распознавание речи с помощью глубоких рекуррентных нейронных сетей», в Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference , (Ванкувер, Британская Колумбия: IEEE), 6645–6649.
Google Scholar
Грефф К., Шривастава Р. К., Коутник Дж., Стойнебринк Б. Р. и Шмидхубер Дж. (2016). LSTM: поисковая космическая одиссея. IEEE Trans. Neural Netw. Учить. Syst. 28, 2222–2232. DOI: 10.1109 / TNNLS.2016.2582924
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Güçlü, U., и van Gerven, M.A. (2015). Глубокие нейронные сети обнаруживают градиент сложности нейронных репрезентаций вентрального потока. Дж.Neurosci. 35, 10005–10014. DOI: 10.1523 / JNEUROSCI.5023-14.2015
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хан, К., Вэнь, Х., Ши, Дж., Лу, К.-Х., Чжан, Ю., и Лю, З. (2017). Вариационный автоэнкодер: неконтролируемая модель для моделирования и декодирования активности фМРТ в зрительной коре. bioRxiv 214247. doi: 10.1016 / j.neuroimage.2019.05.039
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хэксби, Дж. В., Гоббини, М.И., Фьюри, М. Л., Ишаи, А., Схоутен, Дж. Л., и Пьетрини, П. (2001). Распределенные и перекрывающиеся изображения лиц и предметов в вентральной височной коре. Наука 293, 2425–2430. DOI: 10.1126 / science.1063736
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хе К., Чжан Х., Рен С. и Сунь Дж. (2016). «Глубокое остаточное обучение для распознавания изображений», в материалах Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , Las Vegas, NV, 770–778.
Google Scholar
Хорикава Т. и Камитани Ю. (2017b). Иерархическое нейронное представление объектов сновидения, выявленных путем декодирования мозга с помощью глубоких нейронных сетей. Фронт. Комп. Neurosci. 11: 4. DOI: 10.3389 / fncom.2017.00004
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кастнер С. и Унгерлейдер Л. Г. (2000). Механизмы зрительного внимания в коре головного мозга человека. Annu. Rev. Neurosci. 23, 315–341.
PubMed Аннотация | Google Scholar
Кеткар, Н. (2017). «Введение в pytorch», в Deep Learning with Python , ed. Н. Кеткар (Беркли, Калифорния: Апресс), 195–208. DOI: 10.1007 / 978-1-4842-2766-4_12
CrossRef Полный текст | Google Scholar
Хан, Ф. С., Ван Де Вейер, Дж., И Ванрелл, М. (2009). «Нисходящее цветовое внимание для распознавания объектов», в материалах Proceedings of the 2009 IEEE 12th International Conference on Computer Vision: IEEE , Kyoto, 979–986.
Google Scholar
Крижевский А., Суцкевер И., Хинтон Г. Э. (2012). «Классификация ImageNet с глубокими сверточными нейронными сетями», Международная конференция по системам обработки нейронной информации , Невада, 1097–1105.
Google Scholar
ЛеКун Ю., Боттоу Л., Бенжио Ю. и Хаффнер П. (1998). Применение градиентного обучения для распознавания документов. Proc. IEEE 86, 2278–2324. DOI: 10.1109 / 5.726791
CrossRef Полный текст | Google Scholar
Ли, К., Сюй Дж. И Лю Б. (2018). Расшифровка естественных изображений вызванных активностью мозга с использованием моделей кодирования с обратимым отображением. Neural Netw. 105, 227–235. DOI: 10.1016 / j.neunet.2018.05.010
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лин, Т.-Й., Гоял, П., Гиршик, Р., Хе, К., и Доллар, П. (2017). «Потеря фокуса для обнаружения плотных объектов», Труды международной конференции IEEE по компьютерному зрению , Венеция, 2980–2988.
Google Scholar
Махендран А., Ведальди А. (2014). «Понимание глубинных представлений изображений путем их инвертирования», в материалах Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , Columbus, OH, 5188–5196.
Google Scholar
Маллат С. и Чжан З. (1993). Сопоставление преследования с частотно-временными словарями. Технический отчет. Courant Inst. Математика. Sci. N. Y. 41, 3397–3415. DOI: 10.1109 / 78.258082
CrossRef Полный текст | Google Scholar
Мартин, Д., Фаулкс, К., Тал, Д., и Малик, Дж. (2001). «База данных сегментированных естественных изображений человека и ее применение для оценки алгоритмов сегментации и измерения экологической статистики», Труды Восьмой Международной конференции IEEE по компьютерному зрению. ICCV , Ванкувер, Британская Колумбия.
Google Scholar
Миколов, Т., Карафят, М., Бургет, Л., Черноцки, Дж., И Худанпур, С. (2010). «Языковая модель на основе рекуррентной нейронной сети», в материалах Proceedings of the 11th Annual Conference of the International Speech Communication Association , Chiba.
Google Scholar
Мисаки М., Ким Ю., Бандеттини П. А. и Кригескорте Н. (2010). Сравнение многомерных классификаторов и нормализации отклика для фМРТ с информацией о паттернах. Neuroimage 53, 103–118. DOI: 10.1016 / j.neuroimage.2010.05.051
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Мишкин М., Унгерлейдер Л. Г., Макко К. А. (1983). Объектное зрение и пространственное видение: два корковых пути. Trends Neurosci. 6, 414–417. DOI: 10.1016 / 0166-2236 (83)
-x
CrossRef Полный текст | Google Scholar
Населарис, Т., Пренгер, Р. Дж., Кей, К. Н., Оливер, М., и Галлант, Дж. Л. (2009). Байесовская реконструкция естественных изображений по активности мозга человека: нейрон. Нейрон 63, 902–915. DOI: 10.1016 / j.neuron.2009.09.006
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ниделл Д., Вершинин Р. (2010). Восстановление сигнала из неполных и неточных измерений с помощью регуляризованного поиска ортогонального согласования. IEEE J. Sel. Вершина. Сигнальный процесс. 4, 310–316. DOI: 10.1109 / jstsp.2010.2042412
CrossRef Полный текст | Google Scholar
Нисимото, С., Ан, Т. В., Населарис, Т., Бенджамини, Ю., Ю., Б., и Галлант, Дж. Л. (2011). Реконструкция визуальных впечатлений от мозговой активности, вызванной естественными фильмами. Curr. Биол. 21, 1641–1646. DOI: 10.1016 / j.cub.2011.08.031
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Норман, К. А., Полин, С.М., Детре, Дж. Дж., И Хаксби, Дж. В. (2006). Помимо чтения мыслей: анализ множественных вокселей данных фМРТ. Trends Cogn. Sci. 10, 424–430. DOI: 10.1016 / j.tics.2006.07.005
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Пападимитриу А., Пассалис Н. и Тефас А. (2018). «Расшифровка общих визуальных представлений деятельности человеческого мозга с помощью машинного обучения», Европейская конференция по компьютерному зрению , Мюнхен, 597–606. DOI: 10.1007 / 978-3-030-11015-4_45
CrossRef Полный текст | Google Scholar
Русаковский, О., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet — задача крупномасштабного визуального распознавания. Внутр. J. Comp. Vis. 115, 211–252. DOI: 10.1007 / s11263-015-0816-y
CrossRef Полный текст | Google Scholar
Шустер М. и Паливал К. К. (1997). Двунаправленные рекуррентные нейронные сети. IEEE Trans. Сигнальный процесс. 45, 2673–2681. DOI: 10.1109 / 78.650093
CrossRef Полный текст | Google Scholar
Зенден, М., Эммерлинг, Т. К., Ван Хоф, Р., Фрост, М. А., и Гебель, Р. (2019). Реконструкция воображаемых букв из ранней зрительной коры обнаруживает тесное топографическое соответствие между визуальными мысленными образами и восприятием. Brain Struct. Функц. 224, 1167–1183. DOI: 10.1007 / s00429-019-01828-6
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ши, Н. (2015). «Отличие нисходящих эффектов от восходящих», в книге Perception and its Modalities , ред.Биггс, М. Маттен и Д. Стоукс (Oxford: Oxford University Press), 73–91.
Google Scholar
Ши, Дж., Вэнь, Х., Чжан, Ю., Хань, К., и Лю, З. (2018). Глубокая рекуррентная нейронная сеть выявляет иерархию памяти процесса во время динамического естественного зрения. Hum. Brain Mapp. 39, 2269–2282. DOI: 10.1002 / hbm.24006
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Сонг, С., Чжан, З., Лонг, З., Чжан, Дж., И Яо, Л. (2011). Сравнительное исследование методов SVM в сочетании с выбором вокселей для классификации категорий объектов на данных фМРТ. PLoS One 6: e17191. DOI: 10.1371 / journal.pone.0017191
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Соргер Б., Райтлер Дж., Дамен Б. и Гебель Р. (2012). Устройство для проверки орфографии на основе фМРТ в реальном времени, сразу обеспечивающее надежную независимую от двигателя связь. Curr. Биол. 22, 1333–1338. DOI: 10.1016 / j.cub.2012.05.022
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Spampinato, C., Palazzo, S., Kavasidis, I., Джордано, Д., Сули, Н., и Шах, М. (2017). «Глубокое обучение человеческого разума для автоматизированной визуальной классификации», в материалах Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , Honolulu, HI, 6809–6817.
Google Scholar
Стокс, М., Томпсон, Р., Кьюсак, Р., и Дункан, Дж. (2009). Нисходящая активация популяционных кодов определенной формы в зрительной коре во время мысленных образов. J. Neurosci. 29, 1565–1572. DOI: 10.1523 / JNEUROSCI.4657-08.2009
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Суцкевер И., Виньялс О., Ле К. В. (2014). «Последовательность для последовательного обучения с помощью нейронных сетей», в Advances in Neural Information Processing Systems , San Francisco, CA, 3104–3112.
Google Scholar
Танака, К. (1996). Нижне-височная кора и предметное зрение. Annu. Rev. Neurosci. 19, 109–139. DOI: 10.1146 / annurev.ne.19.030196.000545
CrossRef Полный текст | Google Scholar
Вэнь, Х., Ши, Дж., Чен, В., и Лю, З. (2018). Глубокая остаточная сеть предсказывает корковое представление и организацию визуальных функций для быстрой категоризации. Sci. Отчет 8: 3752. DOI: 10.1038 / s41598-018-22160-9
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Вэнь, Х., Ши, Дж., Чжан, Ю., Лу, К.-Х., Цао, Дж., И Лю, З. (2017). Нейронное кодирование и декодирование с глубоким обучением для динамического естественного зрения. Cereb. Cortex 28, 4136–4160. DOI: 10.1093 / cercor / bhx268
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Яминь, Д. Л., Хонг, Х., Кадье, К. Ф., Соломон, Э. А., Зайберт, Д., и ДиКарло, Дж. Дж. (2014). Иерархические модели с оптимизацией производительности предсказывают нейронные реакции в высших зрительных кортексах. Proc. Natl. Акад. Sci. США 111, 8619–8624. DOI: 10.1073 / pnas.1403112111
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чжан, Х., Лю, Дж., Хубер, Д. Э., Рит, К.А., Тиан Дж. И Ли К. (2008). Обнаружение лиц на изображениях с чистым шумом: функциональное МРТ-исследование нисходящего восприятия. Нейроотчет 19, 229–233. DOI: 10.1097 / WNR.0b013e3282f49083
PubMed Аннотация | CrossRef Полный текст | Google Scholar
границ | Расшифровка семантического содержания фильмов с естественным движением по активности мозга человека
Введение
В последнее десятилетие появился значительный интерес к расшифровке стимулов или психических состояний по активности мозга, измеренной с помощью функциональной магнитно-резонансной томографии (фМРТ).Ранние результаты в этой области (Kay et al., 2008; Mitchell et al., 2008; Naselaris et al., 2009; Nishimoto et al., 2011) вызвали значительный интерес к перспективам футуристических неинвазивных интерфейсов мозг-компьютер. который может выполнять «чтение мозга». Эти исследования показали, что с помощью BOLD фМРТ можно получить значительно больше информации, чем многие считали ранее (Kay et al., 2008). Кроме того, одно недавнее исследование, проведенное в нашей лаборатории, показало, что с помощью фМРТ можно декодировать появление быстро меняющихся естественных фильмов (Nishimoto et al., 2011), оспаривая распространенное мнение о том, что фМРТ подходит только для изучения медленных явлений. Здесь мы расширяем нашу предыдущую работу, расшифровывая, какие категории объектов и действий присутствуют в естественных фильмах.
Мозговое декодирование можно рассматривать как проблему поиска стимула, S , который, скорее всего, вызвал наблюдаемые жирные ответы, R , при распределении вероятностей P (S | R) . На сегодняшний день для решения этой проблемы использовались два общих подхода: байесовское декодирование и прямое декодирование.При байесовском декодировании создается явная модель P (R | S) , чтобы предсказать ответ на основе стимула. Затем используется правило Байеса для инвертирования условной вероятности: P (S | R) = P (R | S) P (S) / P (R). Этот подход использовался для декодирования внешнего вида и семантической категории статических естественных изображений (Naselaris et al., 2009), визуального внешнего вида естественных фильмов (Nishimoto et al., 2011) и семантической категории изолированных визуальных объектов. или слова (Mitchell et al., 2008). Однако байесовское декодирование требует построения априорного распределения по стимулам, P (S) , и это непрактично, когда пространство декодирования велико (например, при декодировании естественных сцен или фильмов). В некоторых случаях эту проблему можно решить, используя большой эмпирический априор (Naselaris et al., 2009; Nishimoto et al., 2011). Однако у нас нет возможности оценить эмпирическую априорность категорий, появляющихся в естественных фильмах. Это затрудняет применение структуры байесовского декодирования к этой проблеме.
Другой популярный подход к этой проблеме — прямое декодирование. В этом подходе создается явная модель P (S | R) , которая напрямую предсказывает стимул на основе ответа. Прямое декодирование использовалось для декодирования того, какая из двух визуальных категорий просматривается (Haxby et al., 2001; Carlson et al., 2003; Cox and Savoy, 2003), о какой из двух категорий снится субъект (Horikawa et al. ., 2013), и какие объекты присутствуют в статичных естественных визуальных сценах (Stansbury et al., 2013). Однако по ряду причин прямое декодирование обычно не является оптимальным для декодирования объектов и действий в естественных сценах активности мозга. Во-первых, прямое декодирование неявно предполагает, что каждая декодируемая функция независима, но объекты и действия в естественных сценах имеют тенденцию коррелировать друг с другом (хотя недавняя работа нашей лаборатории показала, что можно обойти эту проблему, преобразовав стимулы в пространство характеристик, в котором допущение независимости справедливо Stansbury et al., 2013). Во-вторых, каждый объект или действие имеет множество потенциальных меток категорий, связанных во вложенной иерархической структуре. Например, Mercury Sable 1993 года можно также назвать универсалом , автомобилем , моторным транспортным средством и т. Д. Эти метки не являются независимыми и поэтому не должны декодироваться независимо. Одним из решений этой проблемы было бы декодирование только одной метки в иерархии, такой как категория базового уровня (Rosch et al., 1976), которой в этом примере, вероятно, будет car .Однако декодер категорий базового уровня будет игнорировать сигналы фМРТ, относящиеся к подчиненным категориям (например, универсал или 1993 Mercury Sable ), которые могут нести дополнительную информацию о визуальной сцене. Кроме того, получение меток категорий базового уровня потребует обширного ручного присвоения меток несколькими наблюдателями. По этим причинам здесь мы решили использовать другой подход, в котором мы декодировали категории на многих разных уровнях иерархии одновременно.
Наш подход прямого декодирования, иерархическая логистическая регрессия (HLR), декодирует, какие категории объектов и действий присутствуют в естественных фильмах, одновременно фиксируя иерархические зависимости между ними. Логистическая регрессия — естественный выбор для моделирования системы с гауссовскими входными данными (например, жирным шрифтом) и двоичными выходными данными (такими как наличие или отсутствие определенной категории). Самый простой подход логистической регрессии — это построение отдельной модели для каждой категории. Однако этот подход неявно предполагает, что каждая категория независима от всех остальных.Это предположение явно неверно, когда категории связаны иерархически, и это может привести к бессмысленным результатам, таким как декодирование того, что сцена содержит автомобиль , но не автомобиль .
Мы решили эту проблему, объединив несколько моделей логистической регрессии вместе иерархически. Модель HLR декодирует условную вероятность того, что каждая категория присутствует, при условии, что присутствуют ее гиперонимы (ее вышестоящие или родительские категории в иерархии). Эти условные вероятностные отношения могут быть представлены в виде графической модели (рисунок 1).Графическая модель показывает, например, что совместная вероятность того, что сцена содержит категории автомобиль, автомобиль и универсал (с учетом вектора ответов мозга, R ), может быть разложена на произведение условных вероятности:
P (автомобиль, автомобиль, универсал | R) = P (автомобиль | R) × P (автомобиль | автомобиль, R) × P (универсал | автомобиль, R)
Рисунок 1. Графическая модель иерархической логистической регрессии . Модель иерархической логистической регрессии (HLR) использовалась для фиксации зависимостей между декодируемыми категориями.Здесь показана часть графика WordNet. Белые узлы представляют категории для декодирования. Заштрихованный узел представляет наблюдаемые отклики вокселей. Модель HLR не декодирует каждую категорию из ответов независимо. Вместо этого он декодирует условную вероятность наличия гипонима (подчиненная или дочерняя категория), учитывая, что присутствуют его гиперонимы (вышестоящие или родительские категории). Затем декодированные вероятности гиперонимов и гипонимов умножаются, чтобы вычислить вероятность наличия гипонима.
Таким образом, совместная вероятность того, что сцена содержит автомобили категорий , автомобиль и универсал , равна произведению трех условных вероятностей (обратите внимание, что этот пример упрощен; в наших фактических данных автомобиль равен не категория верхнего уровня). Кроме того, предельная вероятность того, что на месте происшествия присутствует универсал категории , идентична этой совместной вероятности. Эта модель не рассматривает каждую категорию отдельно.Вместо этого предполагается, что каждая категория условно независима от других, учитывая ее гиперонимы. Эта структура налагает разумное ограничение на то, что вероятность того, что автомобиль окажется на месте происшествия, никогда не превышает вероятность того, что автомобиль окажется на месте происшествия.
Чтобы оценить полную модель HLR, мы сначала оценили отдельную логистическую модель для каждой условной вероятности. Каждая логистическая модель предсказывает двоичное присутствие или отсутствие категории с учетом вектора воксельных ответов за несколько предыдущих временных точек, R .Условные вероятности моделировались путем ограничения набора данных, который использовался для оценки модели. Например, для оценки модели условной вероятности того, что автомобиль присутствует, при условии, что присутствует автомобиль , мы использовали только моменты времени, когда присутствовал автомобиль (этот метод имеет побочное преимущество что делает оценку модели намного более эффективной, поскольку большинство условных моделей оцениваются с использованием небольших подмножеств полного набора данных).Логистические модели имеют отдельный вес для каждого из включенных вокселей в каждый момент времени. Чтобы учесть гемодинамическое отставание, также были включены ответы из нескольких временных точек (4, 6 и 8 с после декодирования стимула).
Чтобы определить наличие категории с помощью моделей HLR, мы умножили условные вероятности. Например, чтобы декодировать вероятность того, что автомобиль присутствовал в один момент времени, мы сначала извлекли соответствующие ответы вокселей, а затем использовали условную логистическую модель для оценки вероятности того, что автомобиль присутствовал, учитывая, что автомобиль присутствовал. , а затем использовали другую условную логистическую модель для оценки вероятности наличия автомобиля .Наконец, мы умножили эти вероятности вместе, чтобы найти совместную вероятность того, что автомобиль и автомобиль присутствовали, учитывая ответы вокселей. Из этой формулировки ясно, что вероятность того, что присутствует автомобиль , никогда не может превышать совместную вероятность наличия автомобиля автомобиля и автомобиля , таким образом, соблюдая иерархические отношения между этими категориями.
Мы применили структуру моделирования HLR к ЖИРНЫМ ответам фМРТ, записанным от семи субъектов (рис. 2).Сначала были записаны ответы фМРТ, когда испытуемые смотрели 2 часа естественных фильмов. Семантическая таксономия WordNet (Miller, 1995) использовалась для обозначения основных категорий объектов и действий в каждом секундном сегменте фильмов. Используя 2 часа данных оценки модели, мы затем выбрали 5000 вокселей в коре головного мозга каждого субъекта, которые имели наиболее надежные ответы, связанные с категорией (подробности см. В разделе «Методы»). Метки категорий и ответы жирным шрифтом для 5000 выбранных вокселей были затем использованы для оценки отдельной модели HLR для каждого субъекта.Чтобы протестировать модели HLR, мы записали ЖЕЛТЫЕ ответы одних и тех же испытуемых, пока они смотрели дополнительные 9 минут новых естественных фильмов, которые не использовались для оценки модели. Фильмы о проверке модели были повторены десять раз, и ответы были усреднены по повторам, чтобы уменьшить шум. Наконец, мы использовали модель HLR для каждого субъекта, чтобы расшифровать, какие категории присутствовали в проверочных фильмах.
Рисунок 2. Схема эксперимента . Эксперимент состоял из двух этапов: оценка модели и проверка модели .На этапе оценки модели семи испытуемым были показаны 2 часа естественных фильмов, в то время как ЖИРНЫЕ ответы были записаны с использованием фМРТ. Категории значимых объектов и действий были помечены в каждом сегменте продолжительностью 1 с. Затем были оценены модели прямого декодирования, которые оптимально предсказывали метки на основе линейных комбинаций воксельных ответов. На этапе проверки модели тем же семи испытуемым в течение 9 минут были показаны новые естественные стимулы из фильма, которые не были включены в набор оценочных стимулов.Эти фильмы были повторены десять раз, и ответы были усреднены для уменьшения шума. Затем предварительно оцененные модели использовались для декодирования категорий, присутствующих в фильмах. Для оценки производительности модели декодированные вероятности категорий сравнивались с фактическими метками категорий в отдельном наборе проверки, зарезервированном для этой цели.
Материалы и методы
Субъекты
Функциональные данные были собраны у семи человек. Все субъекты не имели неврологических расстройств и имели нормальное или скорректированное до нормального зрение.Протокол эксперимента был одобрен Комитетом по защите людей в Калифорнийском университете в Беркли. Письменное информированное согласие было получено от всех субъектов. Данные для пяти субъектов, использованных здесь, были такими же, как и данные, использованные в предыдущей публикации (Huth et al., 2012).
Экспериментальный дизайн
Стимулы для этого эксперимента состояли из 129 минут естественных фильмов, взятых из трейлеров к фильмам и других источников. Эти стимулы идентичны тем, которые использовались в более ранних экспериментах нашей лаборатории (Nishimoto et al., 2011; Huth et al., 2012). WordNet использовался для обозначения заметных объектов и действий в каждом сегменте по 1 сек в этих фильмах (Huth et al., 2012). В результате получено 1364 уникальных метки. После добавления гиперинтативных ярлыков общее количество категорий составило 1705.
Сбор и предварительная обработка данных МРТ
Данные
МРТ были собраны на сканере 3T Siemens TIM Trio в Центре визуализации мозга Калифорнийского университета в Беркли с использованием 32-канальной объемной катушки Siemens. Функциональные сканы были собраны с использованием последовательности градиентного эхо-EPI с временем повторения (TR) = 2.0045 с, время эха (TE) = 31 мс, угол поворота = 70 градусов, размер вокселя = 2,24 × 2,24 × 4,1 мм, размер матрицы = 100 × 100, поле зрения = 224 × 224 мм. Образцы всей коры были взяты с использованием 30–32 аксиальных срезов. Специально модифицированный биполярный радиочастотный (RF) импульс возбуждения воды использовался, чтобы избежать сигнала от жира.
Отдельные наборы данных оценки (соответствия) модели и проверки модели (тест) были собраны для каждого субъекта с чередованием в течение трех сеансов сканирования. Стимулы для набора данных оценки модели состояли из 120-минутных трейлеров к фильмам.Эти стимулы идентичны стимулам, использованным в Nishimoto et al. (2011) и Huth et al. (2012) и доступны для загрузки с CRCNS: https://crcns.org/data-sets/vc/vim-2/about-vim-2. Функциональные данные для набора данных оценки модели были собраны за 12 отдельных 10-минутных сканирований. Стимулы для набора данных проверки модели состояли из 9-минутных трейлеров к фильмам, повторенных 10 раз. Функциональные данные для набора данных проверки модели были собраны за 9 отдельных 10-минутных сканирований, а затем усреднены. Обратите внимание, что стимулы оценки и проверки были полностью разными; в обоих наборах клипы не появлялись.На протяжении всей презентации стимулов для обоих наборов данных испытуемые зацикливались на точке, которая была наложена на фильм и расположена в центре экрана. Цвет точки менялся четыре раза в секунду для сохранения видимости.
В каждом прогоне корректировка движения производилась с использованием инструмента регистрации линейных изображений FMRIB (FLIRT) из FSL 4.2 (Jenkinson and Smith, 2001). Затем был получен шаблонный объем высокого качества путем усреднения всех объемов в прогоне. FLIRT также использовался для автоматического согласования объема шаблона для каждого прогона с общим шаблоном, который был выбран в качестве шаблона для первого функционального прогона фильма по каждому предмету.Эти автоматические выравнивания были проверены вручную и отрегулированы на точность. Затем матрица перекрестного преобразования была объединена с матрицами преобразования коррекции движения, полученными с помощью MCFLIRT, и объединенное преобразование использовалось для повторной выборки исходных данных непосредственно в общее пространство шаблона.
Для каждого воксела смещение низкочастотного отклика воксела определялось с помощью медианного фильтра с окном 120 с, и оно вычиталось из сигнала. Затем вычитали средний отклик каждого воксела, а оставшийся отклик масштабировали до единичной дисперсии.
Анатомические изображения были получены с использованием импульсной последовательности T1 MP-RAGE. Затем эти изображения были сегментированы для получения трехмерного изображения кортикальной поверхности с использованием программного обеспечения Caret5 (Van Essen et al., 2001).
Оценка модели
Модель HLR включает отдельную модель условной логистической регрессии для каждой категории. Каждая модель условной логистической регрессии преобразует пространственно-временной паттерн активности вокселей в двоичное присутствие (1) или отсутствие (0) одной категории для временных точек, где присутствуют все гиперонимы этой категории.В то время как кора головного мозга содержит десятки тысяч вокселей, многие воксели очень шумны или содержат мало информации о стимулах. Таким образом, чтобы уменьшить сложность модели и уменьшить шум, только 5000 вокселей для каждого объекта использовались в качестве входных данных для модели HLR. (Модели были протестированы на одном субъекте с использованием 1000, 5000 и 10000 вокселей. Наилучшая производительность была обнаружена при 5000 вокселов.) Чтобы найти лучшие 5000 вокселей для каждого объекта, мы сначала использовали регуляризованную линейную регрессию для оценки независимой модели кодирования для каждого объекта. воксель (модели кодирования предсказывают отклик отдельных вокселей как взвешенную сумму по меткам двоичных категорий).Эта процедура моделирования повторялась 50 раз, каждый раз удерживая и прогнозируя ответы на отдельном сегменте набора данных оценки модели. Затем характеристики прогнозирования модели были усреднены по 50-кратным значениям и были отобраны 5000 лучших вокселей. Для этой процедуры использовался набор данных оценки модели, данные валидации были зарезервированы для использования в другом месте.
Для каждой сцены пространственно-временными входными данными для модели HLR является вектор длиной 15000, состоящий из ЖИРНЫХ ответов для 5000 выбранных вокселей в трех последовательных временных точках.Было включено несколько временных точек, потому что ЖИРНЫЕ ответы медленные, через 5–15 секунд на подъем и спад после нейронного события (Boynton et al., 1996). Включение нескольких временных точек в модель позволяет процедуре регрессии изучить линейный фильтр, который будет деконволюционировать медленную ЖИРНУЮ функцию отклика из временного хода стимула. Таким образом, для прогнозирования наличия категории в момент времени t , модель использует воксельные ответы на временах t + 2, t + 3 и t + 4 TR.При TR 2 с эти задержки соответствуют 4, 6 и 8 с.
Для построения каждой модели условной логистической регрессии мы использовали только подмножество данных оценки модели, в котором присутствовали все гиперонимы выбранной категории. Например, для построения модели для категории спорткара мы выбрали все временные точки, в которых присутствовал автомобиль . Затем модель была оценена с использованием градиентного спуска с ранней остановкой. Сначала данные были разбиты на два набора: 90% данных использовались для градиентного спуска, а 10% использовались для оценки точки остановки.На каждой итерации веса обновлялись на основе данных градиентного спуска, а затем ошибка модели оценивалась с использованием данных ранней остановки. Если ошибка данных ранней остановки не уменьшалась в течение десяти последовательных итераций, процедура градиентного спуска прекращалась. Веса вокселей были инициализированы равными нулю, а член смещения был установлен для получения априорной вероятности категории с учетом ее гиперонима (априорная вероятность была вычислена эмпирически по всему набору обучающих данных). Каждая модель оценивалась трижды с использованием отдельных наборов данных для ранней остановки, а затем полученные веса были усреднены.
Мы проверили, дает ли этот градиентный спуск с ранней остановкой результаты, отличные от более стандартной регрессии с L2-штрафом, но обнаружили очень небольшую разницу. Мы реализовали регуляризованную логистическую регрессию L2 с помощью scikit-learn (Pedregosa et al., 2011) с коэффициентами регуляризации от 10 −6 до 10 4 . Для каждого из трех бутстрапов мы подбирали модель для 90% данных и оценивали потери на 10%, чтобы выбрать лучший коэффициент регуляризации.Затем мы взяли средний коэффициент регуляризации, найденный по бутстрапам, и использовали его для корректировки модели на всем обучающем наборе. Мы сравнили результаты этой процедуры с результатами, использующими подход раннего прекращения, и обнаружили, что в среднем регрессия с ранним прекращением работала немного лучше. Для всех категорий с AUC> 0,5 для любого метода регрессии AUC ранней остановки были в среднем выше на 0,09, а 59,0% категорий лучше декодировались моделью ранней остановки, чем регуляризацией L2.Эти различия, по-видимому, связаны с тем, что ранняя остановка намного лучше справляется с категориями с небольшим количеством положительных примеров.
Чтобы избежать переобучения, выходные данные модели были сглажены до исходной априорной вероятности. Мы предположили, что бета-версия распределена по выходным данным модели, со средним значением, равным условной априорной вероятности для каждой категории. Затем мы подбираем параметр масштабирования η таким образом, что P * (Si | S \ i, R) = P (Si | S \ i, R) + ηPi, 01 + η максимизирует логарифмическую вероятность 1 мин удерживаемых данных (где P ( S i | S \ i , R ) — результат логистической модели для ярлыка i th с учетом ярлыков и ответов других категорий, и P i , 0 — априорная вероятность увидеть i -ю метку при наличии ее гиперонимов).Эта сглаженная вероятность использовалась во всех последующих анализах.
Затем все модели отдельных категорий были объединены, чтобы сформировать модель HLR, которая описывает полное распределение вероятностей по всем меткам сцены.
Оценка модели с шумом на этикетке
Одна потенциальная проблема с описанным выше подходом логистической регрессии заключается в том, что присвоенные вручную метки категорий в наборе данных оценки модели могут быть неточными или зашумленными. Чтобы учесть эту возможность, мы повторно оценили модели логистической регрессии для одного субъекта, используя метод из (Bootkrajang and Kabán, 2012), который итеративно оценивает матрицу вероятности переворота метки 2 × 2 для каждой категории, где первая строка представляет собой вероятность получение метки 0 или 1 при условии, что истинная метка равна 0, а вторая строка — это вероятность получения 0 или 1 при условии, что истинная метка равна 1.Мы дважды переоценили каждую модель логистической регрессии: сначала инициализировали все веса модели до нуля, а затем инициализировали веса модели значениями, найденными с использованием нашего более раннего подхода логистической регрессии. В обоих случаях мы инициализировали вероятность ошибки метки (т.е. недиагональные значения в матрице переворачивания метки) равной 0,1. Для обоих условий матрица переворачивания быстро сходилась к единичной матрице почти в каждой категории. Максимальная предполагаемая вероятность ошибки на этикетке равнялась 0.0086 (т.е. менее 1%). Это говорит о том, что матрицы переворачивания меток для этого эксперимента практически неотличимы от единичной матрицы. Вероятно, это связано с тем, что наши стимулы были помечены вручную одним человеком, а не с использованием краудсорсингового подхода, такого как Механический турок Amazon.
Оценка модели
Анализ рабочих характеристик приемника (ROC)
Для каждой временной точки в наборе данных проверки мы спрогнозировали вероятность того, что каждая категория присутствовала в стимуле, используя HLR.Затем ROC-анализ был использован для оценки производительности декодирования модели для каждой категории. Для проведения ROC-анализа мы постепенно увеличивали порог обнаружения с нуля до единицы. Для каждого порога мы вычислили количество ложноположительных обнаружений (точки, где прогнозируемый временной ход выше порогового значения, но категория отсутствует) и истинно положительных обнаружений (когда прогнозируемый временной ход выше порогового значения, а категория фактически равна присутствует в стимуле). Затем мы построили график истинно положительной скорости (TPR) против ложноположительной скорости (FPR) для всех пороговых значений, создав кривую ROC.
Обычной статистикой, используемой для измерения эффективности обнаружения, является площадь под кривой ROC (AUC). Значение AUC, равное 1,0, представляет идеальное декодирование, при котором вероятность декодирования для любого момента времени, в котором категория фактически присутствует, выше, чем вероятность декодирования для каждого момента времени, в котором категория отсутствует. Мы определили уровень вероятности AUC, перетасовывая фактические двоичные метки для каждой категории во времени. Блоки из четырех ТУ перетасовывались 1000 раз, чтобы получить новые временные курсы с той же априорной вероятностью и автокорреляционной структурой, аналогичной исходным данным (мы протестировали блоки других размеров, но не обнаружили разницы в результатах).Затем вычислялась AUC для каждого из 1000 перетасованных временных курсов, и нулевое распределение AUC соответствовало бета-распределению с центром на 0,5. Наконец, мы вычислили вероятность получения фактического AUC при этом распределении. Фактическая AUC была объявлена значимой, если ее вероятность при этом нулевом распределении была ниже порога значимости. Пороги значимости были определены путем применения процедуры Бенджамини-Хохберга (Benjamini and Hochberg, 1995), чтобы ограничить частоту ложных открытий, q (FDR) , при множественных сравнениях до 0.01.
Вероятность модели
Анализ ROC проверяет, насколько хорошо каждая категория декодируется за все время. Однако также важно проверить, насколько хорошо все категории декодируются в каждый момент времени. Чтобы проверить это, мы рассчитали вероятность фактических меток категорий в каждый момент времени с учетом декодированных вероятностей категорий. Эта вероятность была вычислена как произведение вероятностей получения фактической двоичной метки для каждой категории в рамках модели. Для нулевой модели мы использовали априорную вероятность согласно набору данных оценки модели, которая была постоянной во времени.Затем мы количественно оценили производительность модели как отношение относительного логарифмического правдоподобия между моделью HLR и нулевой моделью. Чтобы оценить уровень вероятности, мы перетасовали выходные данные модели для каждой категории по времени 100 000 раз, повторно вычисляя логарифмическое отношение правдоподобия при каждой перетасовке. Относительное логарифмическое правдоподобие было объявлено значимым, если вероятность при перемешанном распределении была ниже порога значимости ( p < 0,01 ).
Результаты
Характеристики декодирования для отдельных категорий
На рисунке 3 показана производительность декодирования модели HLR для одного субъекта для нескольких различных категорий: разговор, животное, транспортное средство и вещь (аналогичные графики для других шести субъектов показаны на дополнительных рисунках 1–7).Панели в левой части рисунка показывают временной ход декодированной категории в наборе данных проверки модели. Заштрихованные области указывают периоды, когда категория действительно присутствовала. Панели в правой части рисунка показывают кривую рабочей характеристики приемника (ROC) для декодера соответствующей категории. Заштрихованная область под кривыми ROC показывает плотность нулевого распределения кривых ROC, которая была определена путем перетасовки. Все AUC, показанные на этом рисунке, значительно больше, чем ожидалось случайно (q (FDR) <0.01).
Рис. 3. Временные курсы декодирования и характеристики декодирования одного предмета для четырех отдельных категорий . Результаты для четырех из 479 категорий, расшифрованных в этом исследовании. ( слева, ) Каждая строка дает декодированную вероятность того, что определенная категория объекта или действия присутствовала в фильме с течением времени. Синие линии показывают вероятность декодирования, а серые области показывают моменты времени, когда категория действительно присутствовала в фильме. Расшифрованные вероятности для глагола говорить и существительного животное высоки, когда присутствуют эти категории, и ниже в другое время.Однако вероятности не точны во времени. Например, на 2,7 мин после начала фильма разговор появляется для одного момента времени, но декодированная вероятность требует нескольких моментов времени для повышения и понижения. Декодированные вероятности существительного средство передвижения и существительного вещь (в частности, вещь.n.12 , которая включает такие разные категории, как водоем и часть тела ) менее точны, чем talk или животное .Однако модель декодирования правильно приписывает низкую достоверность своим предсказаниям, о чем свидетельствует тот факт, что вероятность декодирования для вещи колеблется около предшествующего значения 0,32. ( Справа ) Анализ рабочих характеристик приемника (ROC), обобщающий общую точность декодирования для каждой из четырех категорий. ROC строит график истинных положительных результатов (TPR) как функцию ложных положительных результатов (FPR) декодера. Производительность декодера показана синим цветом. Эффективность была определена путем перетасовки временного курса стимула и пересчета кривой ROC (см. Методы).Распределение кривых по 1000 перетасовкам показано на том же графике серым цветом. Площадь под кривой ROC (AUC) показана на каждой панели, а значимые значения (q (FDR) <0,01) отмечены звездочкой. Кривые ROC показывают, что как talk , так и animal декодируются точно, но vehicle и thing декодируются не очень хорошо. Аналогичные графики для других шести субъектов показаны на дополнительных рисунках 1–7.
В первой строке рисунка 3 показан декодированный временной ход для глагола говорить .Вероятности декодирования очень высоки, когда в фильме присутствует разговор, , и относительно низки в другое время. В декодированной временной шкале нет ложноположительных пиков. Однако декодированный временной ход не является точным во времени: для подъема и спада требуется несколько секунд. Например, на 2,7 мин после начала фильма разговор появляется на один момент времени, но вероятность декодирования начинает расти на несколько временных точек раньше, а затем требуется несколько временных точек, чтобы вернуться к базовому уровню после исчезновения категории.Эта временная неточность проявляется даже в том случае, если модель HLR включает ответы от нескольких временных лагов, которые должны частично компенсировать вялый гемодинамический ответ. Это может быть связано с тем, что модель HLR декодирует категории в каждый момент времени независимо и не учитывает категории, декодированные для других моментов времени. Тем не менее, площадь под кривой ROC (AUC) составляет 0,918, демонстрируя, что декодер чрезвычайно точен. Это говорит о том, что кортикальное представление talk достаточно устойчиво, чтобы его можно было надежно декодировать с помощью фМРТ.
Во второй строке рисунка 3 показан расшифрованный временной график для категории животных . AUC для животных составляет 0,911, что снова указывает на чрезвычайно высокую точность декодера. Как и в случае с talk , это говорит о том, что кортикальное представление животного достаточно устойчиво, чтобы его можно было надежно декодировать с помощью фМРТ.
В третьей строке рисунка 3 показан расшифрованный временной ход для категории , автомобиль (это общая категория, которая включает несколько более конкретных категорий, таких как автомобиль , мотоцикл и лодка ).Декодированный временной ход очень высок и составляет 6,1 мин, когда автомобиль фактически присутствует в стимуле. Однако декодированный временной ход был низким в течение нескольких других периодов, когда присутствовало транспортное средство . В другое время, например 0,5 мин, декодированный временной график высокий, но транспортное средство отсутствует. В этом случае AUC составляет 0,758, что указывает на удовлетворительную общую точность декодера. Это предполагает, что кортикальное представление транспортного средства не так надежно или отличительно, как представления talk или животного .
Четвертая строка на Рисунке 3 показывает декодированный временной ход для вещи категории . Thing (а именно thing.n.12 в WordNet) — это категория высокого уровня, которая включает такие категории, как часть тела и водоем . Декодированный временной ход всегда является промежуточным, и есть несколько случаев, когда вероятность декодирования была очень высокой или очень низкой. Точки времени, в которых предмет действительно присутствовал в стимуле, имеют лишь незначительно более высокие вероятности декодирования, чем моменты времени, в которых предмет отсутствовал.Значение AUC 0,694 является статистически значимым, но оно намного ниже, чем значение AUC, полученное для других категорий, представленных здесь. Это говорит о том, что кортикальное представление вещи не отличается от других, более конкретных категорий. Мы считаем, что это потому, что вещь — это искусственная категория, изобретенная WordNet, которая не сильно представлена в мозгу.
Характеристики декодирования для всех категорий
Результаты на Рисунке 3 показали, что декодер не одинаково успешен для всех категорий.Для дальнейшего изучения этой проблемы мы вычислили производительность декодирования (AUC) для всех категорий, которые появились как минимум в 3 временных точках в наборе данных проверки. На рисунке 4 мы показываем эти AUC в виде графика, организованного в соответствии со структурой семантической таксономии WordNet (аналогичные графики для каждого предмета в отдельности показаны на дополнительных рисунках 1–7; 30 наиболее декодируемых категорий по всем предметам перечислены в Дополнительная таблица 1). Здесь цвет каждого узла отражает AUC (интегрированную для всех субъектов), а насыщенность отражает уверенность в оценке AUC.
Рисунок 4. Графическая визуализация точности декодирования . Сюжет оформлен в соответствии с графической структурой WordNet. Кружки и квадраты обозначают 479 категорий, представленных в фильмах, используемых для проверки модели. Кружки обозначают предметы (существительные), а квадраты обозначают действия (глаголы). Производительность декодирования была агрегирована по всем предметам путем объединения декодированных вероятностных временных курсов. Размер каждого маркера обозначает площадь под кривой ROC (AUC) для этой категории в диапазоне от 0.5 к 1.0. Цвета маркера обозначают значение p для AUC этой категории; более глубокий синий отражает большие значения p . Категории, для которых важна точность декодирования, отображаются закрашенными кружками (q (FDR) <0,01). AUC высок для некоторых общих категорий, таких как человек, млекопитающее и артефакт . Это низкое значение для других, таких как вещь, материя, инструментальность и абстракция . Это говорит о том, что некоторые общие категории хорошо представлены в мозгу в масштабе, который можно измерить с помощью фМРТ, а другие нет.AUC обычно низок для определенных категорий, которые встречаются реже. Это не обязательно означает, что редко встречающиеся категории плохо представлены в мозгу; он может просто отражать недостаточные данные. AUC также низка для фоновых категорий, таких как завод, местоположение и атмосферное явление . Это может происходить из-за того, что испытуемые обычно не уделяют должного внимания этим категориям, если это не указано в явной форме. Подобные графики для каждого предмета в отдельности показаны на дополнительных рисунках 1–7.
Многие общие категории, такие как человек, млекопитающее, общаются, и структура , были декодированы точно, что позволяет предположить, что эти категории представлены конкретными последовательными паттернами активности мозга. Напротив, другие общие категории, такие как вещь и абстракция , были декодированы плохо, даже несмотря на то, что мы можем точно декодировать гипонимы (или подчиненные категории) этих плохо декодированных общих категорий. Например, вещь плохо декодируется, но его гипонимы водоем и часть тела декодируются точно.Это говорит о том, что часть тела и водоем представлены очень по-разному, поэтому линейная модель не может декодировать обе категории одновременно. Среди действий (обозначенных квадратными маркерами) мы обнаружили, что коммуникативные глаголы, глаголы путешествий и непереходные движения (например, jump, turn ) обычно значительно и точно декодируются, в то время как глаголы потребления и переходные движения (например, drag, pour ) ) обычно декодировались плохо.
Производительность условного декодирования
Подход HLR предполагает, что кортикальные реакции соответствуют таксономии WordNet, но в некоторых случаях это предположение, вероятно, неверно.Поэтому мы провели анализ, который показывает, какие гипернимые связи в WordNet не отражаются на активности мозга. В рамках подхода HLR мы использовали WordNet для построения условных моделей, которые декодируют наличие данной категории, включая все ее гипонимы. Например, условная модель для автомобиля должна различать любой автомобиль (например, универсал , спортивный автомобиль и т. Д.) И любой другой автомобиль . Эти модели неявно предполагают, что все гипонимы любой данной категории вызывают аналогичные реакции в коре головного мозга (рис. 5).Если это предположение верно, то общая производительность декодирования будет хорошей, но может быть трудно различить категории гипонимов. Если это предположение неверно, то общая производительность декодирования будет низкой, но будет легко различать гипонимы.
Рис. 5. Сравнение условной и полной AUC . HLR предполагает, что структура WordNet отражается в мозге. Однако это может быть не так. Если определенная группа категорий (показанная синими узлами в A ) сильно отражается в мозгу, то можно ожидать, что группа будет сильно отделима от всех других категорий.Эта ситуация показана графически в (B) , где отклики вокселей на несколько категорий нанесены на график в гипотетическом 2-мерном пространстве отклика. Категории внутри группы отображаются синим цветом, а другие категории — серым. Воксельный ответ на категорию, которую мы пытаемся декодировать, показан в виде круга. Здесь синие категории легко линейно отделены от других категорий, что дает высокий общий AUC для выбранной категории. Другая ситуация показана в (C) , где сгруппированные категории не вызывают очень похожих ответов.Здесь выбранную категорию легче отличить от своих братьев и сестер, чем от других категорий, что приводит к высокому cAUC и более низкому общему AUC. Это говорит о том, что для группировок категорий на основе WordNet, которые не отражаются в мозге, cAUC будет значительно выше, чем общая AUC.
Мы использовали эту логику для построения теста для каждой гипернимой связи в подмножестве WordNet, используемом в этом исследовании. Для каждой категории мы вычислили условную AUC (cAUC), используя только моменты времени в наборе данных проверки, когда присутствовали все гиперонимы этой категории.Таким образом, cAUC показывает, насколько хорошо категорию можно отличить от своих братьев и сестер. Затем мы сравнили cAUC с общим AUC для каждой категории. Если cAUC была значительно выше, чем общая AUC, то мы пришли к выводу, что предполагаемая взаимосвязь между этой категорией и ее гипернимом не отражается на активности мозга.
Результаты этого анализа показаны на рисунке 6. Здесь cAUC для каждой категории нанесен на тот же график WordNet, что и на рисунке 4. Размер и цвет каждого узла отражают cAUC соответствующей категории.Для категорий, в которых cAUC значительно выше, чем общий AUC, граница, связывающая эту категорию с ее гиперонимом, окрашена в красный цвет (все значимые взаимосвязи перечислены в дополнительной таблице 2). В общей сложности мы обнаружили, что 17 отношений, представленных WordNet, существенно не соответствовали ответам мозга. Некоторые из существенно противоречивых отношений выделяют категории, которые технически связаны, но сильно отличаются от своих братьев и сестер. Например, растение — единственная неживая ветвь организма , лошадь — единственная лошадь, на которой ездят люди, а пингвин — единственная нелетающая морская птица .Между категориями очень высокого уровня появляются и другие существенно противоречивые отношения, вероятно, отражающие трудный выбор, сделанный при разработке WordNet. Например, отношения между thing (а именно thing.n.12 ) и его гипонимами body part и body кажутся искусственными. В целом, эти результаты показывают несколько взаимосвязей категорий, которые следует пересмотреть, если WordNet будет использоваться для дальнейшего моделирования реакций мозга.
Рисунок 6.Графическая визуализация точности декодирования после кондиционирования родительских категорий . Производительность декодирования для каждой из 479 категорий, обусловленная присутствием их гиперонима в сцене, объединенная по предметам. Рисунок устроен так же, как на рисунке 4. Условная AUC (cAUC) была вычислена только в моменты времени, когда присутствуют гиперонимы категории, что заставляет модель различать родственные категории. Если cAUC для категории больше, чем полный AUC, это означает, что категорию легче отличить от своих братьев и сестер, чем от других категорий.Значимость этой разницы оценивалась для каждого ребра в графе WordNet. Если категория значительно меньше похожа на своих братьев и сестер, чем можно было бы ожидать, ее край окрашивается в красный цвет. Таким образом, связи WordNet между категориями, которые не связаны между собой в мозгу, отображаются красным цветом. Края между предметом и его гипонимом водоем и частью тела отображаются красными, потому что эти категории не представлены одинаково в мозгу. Кроме того, граница между организмом и растением кажется красной, вероятно потому, что растение является единственным неживым гипонимом организма .Категории, для которых условная энтропия слишком мала для надежной оценки cAUC, окрашены в серый цвет.
Производительность декодирования для отдельных моментов времени
\
Модель HLR восстанавливает информацию о наличии отдельных категорий в стимуле, но в естественных фильмах много разных категорий появляется в каждый момент времени. Чтобы проверить, насколько хорошо модель HLR декодирует все категории, присутствующие в каждый момент времени, мы вычислили вероятность фактических категорий, присутствующих в стимулах, S ( t ), учитывая оценки модели, θ (t) = Р ^ (S (t) | R).Чтобы сравнить с уровнем производительности, который можно было бы ожидать случайно, мы нормализовали это значение на априорную вероятность фактических категорий, P 0 ( S ). Здесь мы аппроксимировали P 0 ( S i ), установив его равным доле времени, в течение которого категория S i присутствовала в фильмах, используемых для оценки параметров модели. . Таким образом, вероятность декодированной категории относительно предыдущей для каждого момента времени определяется выражением:
Рисунок 7 показывает относительную логарифмическую вероятность во времени, усредненную по субъектам (аналогичные графики, показывающие данные для каждого субъекта отдельно, показаны на дополнительных рисунках 1–7).Логарифмические отношения правдоподобия больше нуля указывают периоды, когда оценки модели HLR относительно более вероятны, чем предыдущие, а логарифмические отношения меньше нуля указывают периоды, когда модель относительно менее вероятна, чем предыдущая. На этом рисунке показано, что одни периоды в фильме декодируются лучше, чем другие. Изучение стимулов, появившихся во время пиков и спадов в производительности декодирования, показывает, что декодирование наиболее точно для подводных сцен и сцен, в которых присутствует один человек.Эти сцены содержат только несколько категорий, каждая из которых хорошо смоделирована декодером. Мы наблюдаем слабую тенденцию к более низким относительным логарифмическим отношениям, когда количество категорий в сцене больше (см. Дополнительный рисунок 8), а декодирование относительно плохое для сцен, которые содержат необычные категории (например, сцена крупным планом, в которую наливают вино. бокал) и для временных точек, содержащих переходы между сценами.
Рис. 7. Общая производительность декодирования в каждый момент времени для всех категорий объектов и действий .Здесь результаты в каждый момент времени были усреднены по всем пяти предметам. Точность декодирования выражается как логарифмическая вероятность фактических меток категорий для данной модели относительно априорной вероятности того, что каждая категория присутствует. Значения, равные нулю, указывают на то, что модель работает так хорошо, как можно было бы ожидать, просто предполагая на основе априорных вероятностей. Заштрихованные области показывают, что производительность значительно выше вероятности ( p <0,01 без исправлений, тест перестановки). Вверху показаны два примера хорошо декодированных моментов времени.На одном изображен идущий человек, на другом - подводная сцена, изображающая косяк рыб. Это простые и стереотипные сцены, которые можно точно декодировать. Внизу показаны два примера плохо декодированных моментов времени. Один представляет собой переход между сценами прыжка лошади и пьющей женщины, другой - крупным планом глаза оленя. Сцена перехода не может быть декодирована точно из-за плохой временной точности декодера. Глаз оленя - нетипичная сцена, которая редко встречается в стимулах, используемых для оценки воксельных моделей.Подобные графики, показывающие данные по каждому предмету отдельно, показаны на дополнительных рисунках 1–7.
Сравнение оригинальных фильмов с декодированными категориями
Чтобы обеспечить интуитивно понятную и доступную демонстрацию производительности HLR-декодера, мы создали составное видео, которое показывает стимулирующий фильм слева, а категории с наивысшей вероятностью декодирования — справа (см. Дополнительное видео 1). Размер каждой метки соответствует прогнозируемой вероятности наличия категории.Обратите внимание, что показанные здесь стимулы взяты из набора для проверки модели и не использовались для обучения декодера. Эта демонстрация показывает, что декодер успешно восстанавливает информацию о многих категориях независимо от конкретного содержания фильма.
Отображение весов модели декодирования в Cortex
Поскольку декодер HLR, кажется, способен восстанавливать многие категории объектов и действий из ЖИРНЫХ ответов, естественно может возникнуть вопрос, какие воксели используются для декодирования каждой категории.Однако обратите внимание, что результаты декодирования следует интерпретировать с осторожностью; вопрос о том, какие воксели участвуют в декодировании, не эквивалентен вопросу о том, какие воксели представляют информацию о категории (Haufe et al., 2014; Weichwald et al., 2015). Вокселы, которые имеют малые (или нулевые) веса декодирования для категории, могут по-прежнему представлять информацию об этой категории, но если воксель также представляет информацию о других категориях, то это может быть не особенно полезно для декодирования. И наоборот, вокселы, которые имеют большие веса декодирования, могут не представлять информацию о категории, но вместо этого могут быть коррелированы (или антикоррелированы) с шумом в вокселях, которые действительно представляют эту категорию.Эти проблемы интерпретации гораздо менее серьезны для моделей кодирования (Huth et al., 2012), которые предсказывают ответы на стимулы, а не предсказывают стимулы на основе ответов. Вокселы, которые имеют небольшие веса модели кодирования для категории, скорее всего, не участвуют в представлении этой категории. Вокселы, которые имеют большие веса модели кодирования, либо реагируют непосредственно на категорию, либо на какой-либо аспект стимула, который коррелирует с категорией. По этим причинам мы направляем читателей, интересующихся тем, как эти категории представлены в коре головного мозга, к нашему исследованию модели кодирования, в котором использовался тот же набор данных, что и проанализированный здесь (Huth et al., 2012).
Чтобы проиллюстрировать сложность интерпретации весов модели декодирования, мы нанесли веса декодирования и кодирования для одной категории, человека.n.01 , на плоские корковые карты для одного субъекта (рис. весь набор данных, а не только моменты времени, содержащие гиперонимы человека ). Более ранние исследования показали, что некоторые области мозга избирательно реагируют на человеческие лица и тела, включая веретеновидную и затылочную области лица [FFA Kanwisher et al., 1997 г. и OFA Kanwisher et al., 1997; Halgren et al., 1999] и экстрастриарной области тела (EBA Downing et al., 2001). Поэтому можно наивно ожидать, что вокселям во всех этих областях будут присвоены большие положительные веса в модели декодирования для человек . Однако модель декодирования имеет большие веса только в областях лица (FFA и OFA), но не в области тела (EBA). Таким образом, прямая интерпретация весов модели декодирования приведет к выводу, что EBA не представляет информацию о людях.Напротив, модель кодирования имеет высокий вес в EBA, а также в областях лица, демонстрируя, что EBA, как и ожидалось, действительно реагирует на присутствие людей. Так почему же модель декодирования проигнорировала EBA? Одна возможность предлагается нашим более ранним исследованием модели кодирования, которое показало, что EBA реагирует как на животных, так и на людей, но что FFA и OFA относительно более избирательны для человеческих лиц (Huth et al., 2012). Основываясь на результатах этих моделей кодирования, вывод модели декодирования о том, что EBA не представляет информацию о людях, кажется ложным.Вместо этого мы должны сделать вывод, что EBA представляет информацию о людях в дополнение к другим категориям. Этот пример показывает, что прямая интерпретация весов декодирования может легко привести к ошибочным выводам, и поэтому ее следует избегать, когда это возможно. Вместо этого на вопросы о корковом представительстве следует отвечать, используя подходы кодирования.
Рис. 8. Сглаженные кортикальные карты, показывающие пример веса модели декодирования и кодирования для одной категории . Мы построили веса моделей декодирования и кодирования для одной категории — человека.№ 01 , по одной теме. Для этой визуализации мы построили модель прямого логистического декодирования для этой категории (т.е. мы не ставили условия для ее гиперонимов). Мы усреднили веса декодирования по трем задержкам в каждом из 5000 вокселей, а затем изменили масштаб полученных средних весов, чтобы получить стандартное отклонение 1,0. Точно так же мы усреднили веса кодирования для тех же 5000 вокселей по трем задержкам, а затем изменили масштаб результатов. Для модели декодирования мы видим большие положительные веса в затылочной области лица (OFA) и веретенообразной области лица (FFA), предполагая, что активность в этих областях предсказывает присутствие человека в визуальной сцене.Для модели кодирования мы также видим положительные веса в OFA и FFA, но некоторые из наиболее положительных весов появляются в экстрастриарной области тела (EBA). Это говорит о том, что присутствие человека в визуальной сцене предсказывает реакцию EBA. Однако отсутствие больших весов EBA в модели декодирования предполагает, что ответы EBA не специфичны для наблюдения за человеком. Это иллюстрирует сложность, присущую интерпретации весов из модели декодирования.
Обсуждение
В этом исследовании мы показали, что можно точно декодировать наличие или отсутствие многих категорий объектов и действий в естественных фильмах по жирным сигналам, измеренным с помощью фМРТ.К ним относятся общие категории, такие как животное и структура , особые категории, такие как собака и стена , и действия, такие как talk и run . Однако точность декодирования для одних категорий была лучше, чем для других. В частности, мы обнаружили, что точность декодирования в целом была лучше для сцен, содержащих относительно меньше категорий, чем для сцен, содержащих относительно большее количество категорий. Это говорит о том, что количество связанной с категорией информации, доступной в ЖИРНЫХ сигналах в каждый момент времени, ограничено.
Наш декодер использовал модель HLR, основанную на графической структуре WordNet, семантическую таксономию, созданную вручную группой лингвистов (Miller, 1995). Этот иерархический подход имеет две важные особенности, которые делают его привлекательным для расшифровки категорий естественных стимулов. Во-первых, он предоставляет средства для одновременного декодирования информации на многих различных уровнях детализации. Это жизненно важно для декодирования естественных стимулов, когда неясно, какой уровень детализации следует использовать для описания какого-либо конкретного объекта или действия.Например, один и тот же объект может быть правильно обозначен как автомобиль , автомобиль, спортивный автомобиль или Ford Mustang . Посредством одновременного декодирования всех уровней детализации модель HLR обходит вопрос о том, какой уровень является наиболее подходящим: сцена с некоторой вероятностью содержит автомобиль , некоторую вероятность содержит автомобиль и так далее. Это позволяет модели HLR декодировать относительно более общие категории, когда определенные категории встречаются нечасто или когда их трудно различить с помощью данных мозга.Например, HLR может показать, что сложно декодировать конкретную категорию Ford Mustang , но легко декодировать автомобиль общей категории . Использование нескольких уровней детализации также позволяет HLR обобщить на новые категории: даже если Ford Mustang не появился в наборе данных оценки модели, HLR может декодировать наличие автомобиля на основе более ранних примеров этой категории.
Вторая важная особенность модели HLR заключается в том, что она использует отношения между категориями для рационального ограничения результатов декодирования.Если бы эти ограничения не были включены, одновременное декодирование иерархически связанных категорий могло бы легко привести к бессмысленным результатам. Например, простой одновременный декодер может обнаружить, что вероятность конкретной сцены, содержащей автомобиль , выше, чем вероятность той сцены, содержащей автомобиль . Это было бы невозможно, поскольку каждый автомобиль также является автомобилем . HLR позволяет избежать этой проблемы, ограничивая вероятность декодирования любой категории максимально равной вероятности декодирования гиперонимов этой категории в WordNet.Этот подход основан на идее, известной как «структурированный результат» или «иерархическое обучение» (DeCoro et al., 2007; Silla and Freitas, 2011), области машинного обучения, связанной с проблемами, в которых выходные данные, как известно, имеют определенные статистические данные. состав. В проблеме декодирования, которую мы здесь рассматриваем, структура вывода определяется иерархией категорий WordNet и знанием того, что категория никогда не может присутствовать, если не присутствуют ее гиперонимы. Эта информация включается в модель с использованием так называемой «местной» или «родственной» политики для выбора отрицательных обучающих примеров для каждой категории (Wiener et al., 1995; Силла и Фрейтас, 2011). Эта номенклатура исходит из того факта, что отрицательные примеры для каждой категории выбираются как моменты времени, когда присутствуют братья и сестры категории (и, таким образом, родитель категории присутствует), но где сама категория отсутствует. Этот подход также может сделать оценку модели более эффективной с точки зрения вычислений без снижения производительности, поскольку он использует только соответствующие обучающие примеры (Fagni and Sebastiani, 2007).
Одна потенциальная проблема с подходом HLR заключается в его неявном предположении, что все гипонимы категории вызывают сходные реакции мозга.Это может привести к проблемам, поскольку отношения категорий исходят из WordNet, которая представляет собой созданную вручную семантическую таксономию и, следовательно, не гарантирует отражения активности мозга. Чтобы решить эту проблему, мы протестировали каждую из взаимосвязей, указанных в подмножестве WordNet, охватываемом нашими стимулами. Это было сделано путем изучения того, насколько легко можно отличить каждую категорию от своих братьев и сестер по одному и тому же гиперониму.
Мы обнаружили, что два конкретных типа отношений WordNet не отражаются в корковых представлениях.Первые — это отношения, которые технически правильны, но в которых конкретная категория не может разделять многие функции с общей категорией. Например, связь между растением и организмом не отражалась в мозговой деятельности, вероятно, потому, что растение является единственным неодушевленным гипонимом организма . Второй тип — это отношения, которые кажутся слишком академичными и могут быть характерны для WordNet. Например, отношения между штукой.№ 12 и его гипонимы часть тела и водоем не отражались в мозговой деятельности, вероятно, из-за того, что часть тела и водоем не являются аналогичными категориями по большинству показателей. Возможно, изменение иерархии WordNet путем удаления или изменения этих плохо представленных отношений на самом деле улучшит производительность декодирования. Изменение WordNet на основе данных мозга также может оказаться полезным для понимания того, как категории представлены в мозге.В будущих исследованиях можно даже заменить WordNet иерархией, полностью изученной на основе данных мозга. Попытки построить иерархию категорий непосредственно из данных мозга уже дали правдоподобные результаты для нескольких категорий (Kriegeskorte et al., 2008).
Одной альтернативой подходу HLR могло бы быть декодирование только категорий «базового уровня» (Rosch et al., 1976). Это упростило бы некоторые аспекты моделирования, поскольку избавило бы от необходимости учитывать отношения между категориями.Кроме того, категории базового уровня могут быть лучше представлены в коре головного мозга, чем категории высшего или подчиненного уровня (Iordan et al., 2015). Однако декодер базового уровня не будет таким мощным, как декодер HLR. Во-первых, категория базового уровня конкретного объекта сильно зависит от контекста (Rosch, 1978). Например, наблюдатели могут согласиться с тем, что категория базового уровня для определенного объекта в городской сцене — это автомобиль , но тот же объект, который видели в автосалоне, можно было бы назвать спортивным автомобилем .Неясно, имеет ли смысл оценивать отдельные модели декодирования для автомобиля и спорткара в этой ситуации. Во-вторых, для декодера категорий базового уровня было бы невозможно обобщить на новые категории. Например, предположим, что несколько сцен в наборе данных проверки содержали поезда, , но эти поезда не появились в наборе данных оценки. В то время как ни модель HLR, ни декодер базового уровня не смогут напрямую декодировать присутствие train , модель HLR может быть способна декодировать присутствие автомобиля на основе других примеров, таких как автомобили, лодки и самолеты.
Другой альтернативой модели HLR могло бы быть представление категорий не как бинарных переменных, а как векторов признаков, вероятностей темы (Stansbury et al., 2013) или значений совместной встречаемости из больших текстовых корпусов (Mitchell et al., 2008 ; Turney, Pantel, 2010; Wehbe et al., 2014; Huth et al., 2016). Этот тип модели будет иметь несколько преимуществ перед двоичными декодерами. Во-первых, основанный на признаках декодер может улучшить обобщение, потому что он потребует только, чтобы все признаки присутствовали в стимуле оценки, и не обязательно, чтобы присутствовала каждая отдельная категория.Во-вторых, модель HLR предполагает, что каждая категория не зависит от любой другой категории с учетом ее гиперонимов. Это предположение во многих случаях явно неверно (Blei et al., 2003; Stansbury et al., 2013). Например, хотя car и road являются дальними родственниками в таксономии WordNet, они сильно коррелируют в естественных стимулах. Декодер, который принимает во внимание эти статистические отношения, может комбинировать информацию из категорий, которые не связаны напрямую в таксономии WordNet, что потенциально может улучшить производительность декодирования.
В последние годы область чтения мозга вызвала значительный интерес как у ученых, так и у общественности. Каждое усовершенствование технологии измерения мозга приближает нас к цели создания универсального устройства для считывания состояния мозга человека. С этой целью разработанная здесь модель HLR улучшила нашу способность одновременно декодировать множество переменных, соблюдая при этом некоторые статистические зависимости между ними. Тем не менее, многие проблемы, связанные с чтением мозга, остаются нерешенными.Мы считаем, что наиболее важным теоретическим ограничением является то, что все современные методы (включая HLR) предполагают независимость между переменными, которые на самом деле не являются независимыми. Одним из примеров является предположение, что каждая категория в сцене возникает независимо, как обсуждалось выше. Другой пример — это предположение, что стимулы независимы от момента времени к моменту времени. Ослабление этих предположений должно улучшить производительность будущих декодеров мозга. Будущий идеальный декодер должен улавливать как можно больше этих зависимостей между переменными стимула, тем самым сводя к минимуму количество информации, необходимой для декодирования стимулов.
Взносы авторов
AH и TL разработали и выполнили анализ при участии NB, JG, SN и AV. AH, NB, AV и SN собрали данные. С.Н. разработал стимул. AH пометил семантические категории в стимуле. AH и TL написали статью при участии NB, SN, JG и AV. JG курировал все этапы исследования.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотели бы поблагодарить Джеймса Гао и Толгу Чукур за их помощь в этом проекте. Работа была поддержана грантами Национального института глаз (EY019684), Центра науки информации (CSoI) и Научно-технологического центра NSF в рамках грантового соглашения CCF-0939370. AH также был поддержан нейролингвистическим сообществом Уильяма Орра Дингуолла.
Дополнительные материалы
Дополнительные материалы к этой статье можно найти в Интернете по адресу: https: // www.frontiersin.org/article/10.3389/fnsys.2016.00081
Список литературы
Бенджамини Ю. и Хохберг Ю. (1995). Контроль ложного обнаружения: практичный и эффективный подход к множественному тестированию. J. R. Stat. Soc. Сер. В . 57, 289–300.
Google Scholar
Блей Д. М., Нг А. Ю. и Джордан М. И. (2003). Скрытое размещение Дирихле. J. Mach. Учить. Res. 3, 993–1022.
Google Scholar
Буткраджанг, Дж., и Кабан, А. (2012). Метка-шум Робастная логистическая регрессия и ее приложения . Lect Notes Comput Sci (включая Subser Lect Notes Artif Intell Lect Notes Bioinformatics) 7523 LNAI, 143–158.
Бойнтон, Г. М., Энгель, С. А., Гловер, Г. Х., и Хигер, Д. Дж. (1996). Анализ линейных систем функциональной магнитно-резонансной томографии человека V1. J. Neurosci. 16, 4207–4221.
PubMed Аннотация | Google Scholar
Карлсон, Т.А., Шратер, П., и Он, С. (2003). Паттерны деятельности в категориальных представлениях предметов. J. Cogn. Neurosci. 15, 704–717. DOI: 10.1162 / jocn.2003.15.5.704
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кокс, Д. Д., и Савой, Р. Л. (2003). Функциональная магнитно-резонансная томография (фМРТ) «чтение мозга»: обнаружение и классификация распределенных паттернов активности фМРТ в зрительной коре головного мозга человека. Neuroimage 19, 261–270. DOI: 10.1016 / S1053-8119 (03) 00049-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
ДеКоро, К., Баруткуоглу, З., Фибринк, Р. (2007). «Байесовское агрегирование для иерархической классификации жанров», в ISMIR (Вена).
Google Scholar
Даунинг П. Э., Цзян Ю., Шуман М. и Канвишер Н. (2001). Область коры, отобранная для визуальной обработки человеческого тела. Наука 293, 2470–2473. DOI: 10.1126 / science.1063414
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Fagni, T., and Sebastiani, F. (2007).«О выборе отрицательных примеров для иерархической категоризации текста», Proceedings 3rd Lang Technology Conference (Poznan), 24–28.
Google Scholar
Халгрен, Э., Дейл, А. М., Серено, М. И., Тутелл, Р. Б., Маринкович, К., и Розен, Б. Р. (1999). Расположение избирательной коры человеческого лица по отношению к ретинотопным областям. Hum. Brain Mapp. 7, 29–37.
PubMed Аннотация | Google Scholar
Haufe, S., Meinecke, F., Görgen, K., Dähne, S., Haynes, J.D., Haynes, J.-D., et al. (2014). Об интерпретации весовых векторов линейных моделей в многомерной нейровизуализации. Neuroimage 87, 96–110. DOI: 10.1016 / j.neuroimage.2013.10.067
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хэксби, Дж. В., Гоббини, М. И., Фьюри, М. Л., Ишаи, А., Схоутен, Дж. Л., и Пьетрини, П. (2001). Распределенные и перекрывающиеся изображения лиц и предметов в вентральной височной коре. Наука 293, 2425–2430. DOI: 10.1126 / science.1063736
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хут, А.Г., Де Хеер, В.А., Гриффитс, Т.Л., Теуниссен, Ф.Э., и Джек, Л. (2016). Естественная речь раскрывает семантические карты, покрывающие кору головного мозга человека. Природа 532, 453–458. DOI: 10.1038 / nature17637
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Huth, A.G., Nishimoto, S., Vu, A.T., и Gallant, J.Л. (2012). Непрерывное семантическое пространство описывает представление тысяч категорий объектов и действий в человеческом мозгу. Нейрон 76, 1210–1224. DOI: 10.1016 / j.neuron.2012.10.014
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Иордан, М., Грин, М., Бек, Д., и Ли, Ф. (2015). Структура категорий базового уровня постепенно проявляется в вентральной зрительной коре человека. J. Cogn. Neurosci . 27, 1426–1446. DOI: 10.1162 / jocn_a_00790
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Канвишер, Н., Макдермотт, Дж., И Чун, М. М. (1997). Веретенообразная область лица: модуль в экстрастриальной коре головного мозга человека, специализирующийся на восприятии лица. J. Neurosci. 17, 4302–4311.
PubMed Аннотация | Google Scholar
Kriegeskorte, N., Mur, M., Ruff, D. A., Kiani, R., Bodurka, J., Esteky, H., et al. (2008). Сопоставление категориальных представлений объектов в нижней височной коре человека и обезьяны. Нейрон 60, 1126–1141. DOI: 10.1016 / j.neuron.2008.10.043
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Митчелл, Т.М., Шинкарева С.В., Карлсон А., Чанг К.-М., Малав В.Л., Мейсон Р.А. и др. (2008). Прогнозирование активности человеческого мозга, связанной со значениями существительных. Наука 320, 1191–1195. DOI: 10.1126 / science.1152876
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Населарис, Т., Пренгер, Р. Дж., Кей, К. Н., Оливер, М., и Галлант, Дж. Л. (2009). Байесовская реконструкция естественных изображений по активности мозга человека. Нейрон 63, 902–915.DOI: 10.1016 / j.neuron.2009.09.006
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Нисимото, С., Ву, А. Т., Населарис, Т., Бенджамини, Ю., Ю., Б., и Галлант, Дж. Л. (2011). Реконструкция визуальных впечатлений от мозговой активности, вызванной естественными фильмами. Curr. Биол. 21, 1641–1646. DOI: 10.1016 / j.cub.2011.08.031
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Педрегоса, Ф., Вароко, Г., Грамфор, А., Мишель, В., Тирион, Б., Grisel, O., et al. (2011). Scikit-learn: машинное обучение на Python. J. Mach. Учить. Res. 12, 2825–2830.
Google Scholar
Рош, Э. (1978). «Принципы категоризации» в Познание и категоризация , ред. Э. Рош и Б. Ллойд (Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум), 27–48.
Рош, Э., Мервис, К. Б., Грей, В. Д., Джонсон, Д. М., и Бойс-Брем, П. (1976). Основные объекты в природных категориях. Cogn. Psychol. 8, 382–439.DOI: 10.1016 / 0010-0285 (76) -X
CrossRef Полный текст
Силла, К. Н., Фрейтас, А. А. (2011). Обзор иерархической классификации по различным доменам приложений. Данные Мин. Знай. Discov. 22, 31–72. DOI: 10.1007 / s10618-010-0175-9
CrossRef Полный текст | Google Scholar
Стэнсбери Д. Э., Населарис Т. и Галлант Дж. Л. (2013). Статистика естественных сцен учитывает представление категорий сцен в зрительной коре головного мозга человека. Нейрон 79, 1025–1034. DOI: 10.1016 / j.neuron.2013.06.034
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Терни, П. Д., и Пантел, П. (2010). От частоты к значению: векторные пространственные модели семантики. J. Artif. Intell. Res. 37, 141–188. DOI: 10.1613 / jair.2934
CrossRef Полный текст | Google Scholar
Ван Эссен, Д. К., Друри, Х. А., Диксон, Дж., Харвелл, Дж., Хэнлон, Д., и Андерсон, К. Х. (2001). Интегрированный программный комплекс для поверхностного анализа коры головного мозга. J. Am. Med. Поставить в известность. Доц. 8, 443–459. DOI: 10.1136 / jamia.2001.0080443
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Wehbe, L., Murphy, B., Talukdar, P., Fyshe, A., Ramdas, A., and Mitchell, T. (2014). Одновременное выявление паттернов областей мозга, участвующих в различных подпроцессах чтения рассказов. PLoS ONE 9: e112575. DOI: 10.1371 / journal.pone.0112575
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Weichwald, S., Мейер, Т., Озденицци, О., Шёлкопф, Б., и Болл, Т. Гросс-Вентруп, М. (2015). Правила причинной интерпретации для моделей кодирования и декодирования в нейровизуализации. Neuroimage 110, 48–59. DOI: 10.1016 / j.neuroimage.2015.01.036
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Винер Э. Д., Педерсен Дж. О. и Вейгенд А. С. (1995). «Подход нейронной сети к определению тем», в Proceedings of SDAIR-95, 4th Annual Symposium on Document Analysis and Information Retrieval , (Las Vegas, NV), 317–332.
Google Scholar
Декодирование объектов основных категорий из электроэнцефалографических сигналов с использованием вейвлет-преобразования и опорных векторных машин
Адорни Р., Провербио А.М. (2009) Новое понимание эффектов, связанных с категорией имен: является ли возраст приобретения возможным фактором? Поведение Brain Funct 5:33
PubMed Central
PubMed
Статья
Google Scholar
Боттоу Л., Шапель О., ДеКост Д., Уэстон Дж. (2007) Поддержка векторных машинных решателей крупномасштабных ядерных машин.MIT Press, Кембридж
Google Scholar
Chang CY, Chen SJ, Tsai MF (2010) Применение опорно-векторно-машинного метода для выбора признаков и классификации узлов щитовидной железы на ультразвуковых изображениях. Pattern Recognit 43: 3494–3506
Статья
Google Scholar
Choi E, Lee C (2003) Извлечение признаков на основе расстояния Бхаттачарьи. Pattern Recognit 36: 1703–1709
Статья
Google Scholar
Coyle D, Prasad G, McGinnity TM (2005) Подходы к прогнозированию временных рядов для извлечения признаков в интерфейсе мозг-компьютер.IEEE Trans Neural Syst Rehabil Eng 13: 461–467
PubMed
Статья
Google Scholar
Coyle D, McGinnity TM, Prasad G (2006a) Создание непараметрического интерфейса мозг-компьютер с предварительной обработкой прогнозирования нейронных временных рядов. В: 28-я международная конференция IEEE по инженерии в медицине и биологии, стр. 2183–2186
Койл Д., Прасад Дж., Макгиннити TM (2006b) Повышение автономности и вычислительной эффективности самоорганизующейся нечеткой нейронной сети для интерфейса мозг-компьютер.В: Материалы международного всемирного конгресса FUZZ-IEEE по вычислительному интеллекту, стр. 10485–10492
Delorme A, Sejnowski T, Makeig S (2007) Расширенное обнаружение артефактов в данных ЭЭГ с использованием статистики более высокого порядка и независимого компонентного анализа. NeuroImage 34: 1443–1449
PubMed Central
PubMed
Статья
Google Scholar
Demiralp T, Ademoglu A, Schürmann M, Eroglu CB, Başar E (1999) Обнаружение волн P300 в отдельных испытаниях с помощью вейвлет-преобразования.Brain Lang 66 (1): 108–128
CAS
PubMed
Статья
Google Scholar
Fuggetta G, Rizzo S, Pobric G, Lavidor M, Walsh V (2009) Функциональное представление живых и неживых доменов в полушариях головного мозга: комбинированное исследование потенциальной / трансрасовой магнитной стимуляции, связанного с событием. J Cogn Neurosci 21: 403–414
PubMed
Статья
Google Scholar
Гарретт Д., Петерсон Д.А., Андерсон К.В., Таут М.Х. (2003) Сравнение линейных, нелинейных и методов выбора признаков для классификации сигналов ЭЭГ.IEEE Trans Neural Syst Rehabil Eng 11: 141–144
PubMed
Статья
Google Scholar
Gu Y, Farina D, Murguialday AR, Dremstrup K, Montoya P, Birbaumer N (2009) Идентификация в автономном режиме воображаемой скорости движений запястья у парализованных пациентов с БАС из однократной пробной ЭЭГ. Front Neurosci 3: Артикул 62
Хигаши Х, Танака Т., Фунасе А (2009) Классификация однократной пробной ЭЭГ во время воображаемого движения руки путем извлечения ритмического компонента.IEEE Int Conf 987: 2482–2485
Google Scholar
Hoenig K, Sim EJ, Bochev V, Herrnberger B, Kiefer M (2008) Концептуальная гибкость человеческого мозга: динамический набор семантических карт из визуальных, моторных и связанных с движением областей. J Cogn Neurosci 20: 1799–1814
PubMed
Статья
Google Scholar
Hsu CW, Chang CC, Lin CJ (2010) Практическое руководство по поддержке классификации векторов.Биоинформатика 1: 1–16
Google Scholar
Hsu C-W, Lin C-J (2002) Сравнение методов для мультиклассовых опорных векторных машин. IEEE Trans Neural Netw 13 (2): 415–425
PubMed
Статья
Google Scholar
Ince NF, Tewfik A, Arica S (2005) Классификация ЭЭГ движения с локальными дискриминантными основаниями. В: Международная конференция IEEE по акустике, речи и обработке сигналов, стр. 414–416
Johnson JS, Olshausen BA (2003) Динамика нейронных сигнатур распознавания объектов.J Vis 3: 499–512
PubMed
Статья
Google Scholar
Jung TP, Makeig S, Humphries C, Lee TW, McKeown MJ, Iragui V, Sejnowski TJ (2000) Удаление электроэнцефалографических артефактов путем слепого разделения источников. Психофизиология 37: 163–178
CAS
PubMed
Статья
Google Scholar
Кандасвами А., Кумар С.С., Раманатан Р.П., Джаяраман С., Малмуруган Н. (2004) Нейронная классификация звуков легких с использованием вейвлет-коэффициентов.Comput Biol Med 34 (6): 523–537
CAS
PubMed
Статья
Google Scholar
Кештибан А.М., Разми Х., Козехконан М.К. (2011) Комбинированная нейронная сеть LVQ и многомерный статистический метод, использующий вейвлет-коэффициент для классификации сигналов ЭЭГ. В: Международная конференция IEEE по мехатронике (ICM), стр. 809–814
Кифер М. (2001) Перцептивные и семантические источники эффектов, специфичных для категорий: связанные с событиями потенциалы во время категоризации изображений и слов.Mem Cognit 29: 100–116
CAS
PubMed
Статья
Google Scholar
Kressel U (1999) Парная классификация и машины опорных векторов. В: Schölkopf B, Burges C, Smola A (eds) Достижения в методах ядра — поддержка векторного обучения. MIT Press, Кембридж, стр. 255–268
Google Scholar
Кришнан Мукиа М.Р., Раджендра Ачарья У., Лим К.М., Петзник А., Сури Дж.С. (2012) Метод интеллектуального анализа данных для автоматической диагностики глаукомы с использованием спектров более высокого порядка и характеристик энергии вейвлетов.Knowl Based Syst 33: 73–82
Статья
Google Scholar
Lal TN, Schroder M, Hinterberger T, Weston J, Bogdan M, Birbaumer N, Schlkopf B (2004) Поддержка выбора векторного канала в BCI. IEEE Trans Biomed Eng 51: 1003–1010
PubMed
Статья
Google Scholar
Мартинович Дж., Грубер Т., Мюллер М.М. (2008) Кодирование свойств визуальных объектов и их сочетаний в человеческом мозге.PLoS ONE 3 (11): e3781. DOI: 10.1371 / journal.pone.0003781
PubMed Central
PubMed
Статья
Google Scholar
Martinovic J, Mordal J, Wuerger S (2011) Потенциалы, связанные с событиями, обнаруживают раннее преимущество контуров яркости при обработке объектов. J Vis 11: 1–15
PubMed
Статья
Google Scholar
Merry RJE (2005) Теория всплесков и приложения: исследование литературы.Technische Universiteit Eindhoven, Eindhoven
Messer SR, Agzarian J, Abbott D (2001) Оптимальное шумоподавление вейвлетов для фонокардиограмм. Microelectron J 32 (12): 931–941
Статья
Google Scholar
Milgram J, Cheriet M, Sabourin R (2006) «Один против одного» или «один против всех»: что лучше для распознавания рукописного ввода с помощью SVM? В: Десятый международный семинар по границам распознавания почерка: inria-00103955, версия 1
Miller GA, Lutzenberger W, Elbert T (1991) Проблема связанных ссылок в записи ЭЭГ и ERP.J Psychophysiol 5: 279–280
Google Scholar
Misaki M, Kim Y, Bandettini PA, Kriegeskorte N (2010) Сравнение многомерных классификаторов и нормализации ответов для фМРТ с информацией о паттернах. NeuroImage 53: 103–118
PubMed Central
PubMed
Статья
Google Scholar
Muller KR, Tangermann M, Dornhege G, Krauledat M, Curio G, Blankertz B (2008) Машинное обучение для однократного ЭЭГ-анализа в реальном времени: от взаимодействия мозга с компьютером до мониторинга психического состояния.J Neurosci Methods 167: 82–90
PubMed
Статья
Google Scholar
Паланиаппан Р., Парамесран Р., Нишида С., Сайваки Н. (2002) Новый дизайн интерфейса мозг-компьютер с использованием нечеткого ARTMAP. IEEE Trans Neural Syst Rehabil Eng 10: 140–142
PubMed
Статья
Google Scholar
Paz-Caballero D, Cuetos F, Dobarro A (2006) Электрофизиологические доказательства естественной / искусственной диссоциации.Brain Res 1067: 189–200
CAS
PubMed
Статья
Google Scholar
Перейра Ф., Митчелл Т., Ботвиник М. (2009) Классификаторы машинного обучения и фМРТ: обзор учебного пособия. NeuroImage 45: 199–209
Статья
Google Scholar
Peters BO, Pfurtscheller G, Flyvbjerg H (2001) Автоматическая дифференциация многоканальных сигналов ЭЭГ. IEEE Trans Biomed Eng 48: 111–116
CAS
PubMed
Статья
Google Scholar
Philiastides MG, Sajda P (2005) Временная характеристика нейронных коррелятов принятия перцептивных решений в человеческом мозге.Cereb Cortex 16: 509–518
PubMed
Статья
Google Scholar
Phillips S, Takeda Y, Singh A (2012) Интеграция визуальных признаков, на которую указывают синхронизированные по фазе фронтально-теменные сигналы ЭЭГ. PLoS ONE 7 (3): e32502. DOI: 10.1371 / journal.pone.0032502
CAS
PubMed Central
PubMed
Статья
Google Scholar
Pregenzer M, Pfurtscheller G (1999) Выбор частотной составляющей для интерфейса между мозгом и компьютером на основе ЭЭГ.IEEE Trans Rehabil Eng 7: 413–419
CAS
PubMed
Статья
Google Scholar
Proverbio AM, Del Zotto M, Zani A (2007) Появление семантической категоризации в ранней визуальной обработке: индексы ERP распознавания животных и артефактов. BMC Neurosci 8: 8–24
Статья
Google Scholar
Pulvermuller F, Lutzenberger W, Preissl H (1999) Существительные и глаголы в неповрежденном виде: свидетельства связанных с событием потенциалов и высокочастотных корковых реакций.Cereb Cortex 9: 497–506
CAS
PubMed
Статья
Google Scholar
Rafiee J, Rafiee MA, Prause N, Schoen MP (2011) Базовые функции вейвлетов в биомедицинской обработке сигналов. Expert Syst Appl 38: 6190–6201
Статья
Google Scholar
Sanei S, Chambers JA (2007) Обработка сигналов ЭЭГ. Вили, Нью-Йорк. ISBN-10: 0470025816
Шервуд Дж., Дерахшани Р. (2009) О классифицируемости вейвлет-характеристик для интерфейсов мозг-компьютер на основе ЭЭГ.В: Международная объединенная конференция по нейронным сетям (IJCNN), стр. 2895–2902
Симанова И., Ван Гервен М., Остенвельд Р., Хагоорт П. (2010) Идентификация категорий объектов из ERP для декодирования концептуальных представлений. PLoS ONE 5 (12): e14465. DOI: 10.1371 / journalpone0014465
CAS
PubMed Central
PubMed
Статья
Google Scholar
Subasi A (2005) Автоматическое распознавание уровня бдительности по ЭЭГ с использованием нейронной сети и вейвлет-коэффициентов.Expert Syst Appl 28: 701–711
Статья
Google Scholar
Sykacek P, Roberts S, Stokes M, Curran E, Gibbs M, Pickup L (2003) Вероятностные методы в исследовании BCI. IEEE Trans Neural Syst Rehabil Eng 11: 192–195
CAS
PubMed
Статья
Google Scholar
Tzovara A, Murray MM, Plomp G, Herzog MH, Michel CM, DeLucia M (2012) Расшифровка информации, связанной со стимулом, из однократных пробных ответов ЭЭГ на основе топографии напряжения.Pattern Recognit 45: 2109–2122
Статья
Google Scholar
Вапник В.Н. (1998) Статистическая теория обучения, 1-е изд. Уайли, Нью-Йорк
Google Scholar
Wolpaw JR, Birbaumer N, McFarland DJ, Pfurtscheller G, Vaughan TM (2002) Интерфейсы мозг – компьютер для связи и управления. J Clin Neurophysiol 113: 767–791
Статья
Google Scholar
Zhang A, Yang B, Huang L (2008) Извлечение характеристик сигнала ЭЭГ с использованием спектральной энтропии мощности.IEEE Int Conf Biomed Inform 978: 435–438
Google Scholar
.